Data scope: latest completed health assessments and active unresolved, non-dismissed analysis issues for 24 benchmark projects, pulled on April 13, 2026. Included projects: 14 heritage (Starship, Traefik, Terraform, Deno, Next.js, Prometheus, Grafana, Mattermost, scikit-learn, Kubernetes, Django, Excalidraw, gh CLI, Appwrite) and 10 AI-heavy (Supabase, Twenty, NocoDB, Cal.com, n8n, Dify, LibreChat, Vinext, Open SaaS, Bitchat). Excluded: wttr-benchmark-*, wttr.in, and the AI agent projects (Goose, OpenCode, Codex, Gemini CLI, OpenHands, Sweep).
Score Tables
Heritage
| Project | Overall | Grade | Security | Runtime | Testing | Code Smell | Dead Code | Consistency | Duplication | Compliance | LOC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Starship | 99.5 | A+ | 100.0 | 99.5 | 97.8 | 99.8 | 100.0 | 99.8 | 100.0 | 100.0 | 41,209 |
| Traefik | 97.9 | A+ | 100.0 | 96.6 | 98.9 | 88.3 | 100.0 | 99.7 | 100.0 | 100.0 | 163,262 |
| Terraform | 92.7 | A | 93.1 | 70.3 | 99.4 | 95.4 | 100.0 | 99.8 | 100.0 | 100.0 | 456,581 |
| Deno | 90.6 | A | 84.2 | 97.9 | 81.6 | 89.3 | 93.7 | 93.8 | 100.0 | 100.0 | 592,258 |
| Next.js | 87.8 | A- | 91.7 | 72.5 | 74.8 | 93.6 | 98.2 | 94.7 | 100.0 | 100.0 | 1,832,916 |
| Prometheus | 85.2 | A- | 100.0 | 90.2 | 26.0 | 95.2 | 100.0 | 99.8 | 100.0 | 100.0 | 291,892 |
| Grafana | 80.2 | B+ | 50.6 | 93.3 | 65.3 | 90.6 | 95.3 | 99.9 | 100.0 | 100.0 | 2,123,247 |
| Mattermost | 79.4 | B | 43.5 | 99.1 | 64.4 | 89.8 | 96.8 | 99.0 | 100.0 | 100.0 | 1,359,748 |
| scikit-learn | 79.2 | B | 54.5 | 85.0 | 59.1 | 97.6 | 100.0 | 91.3 | 100.0 | 100.0 | 351,475 |
| Kubernetes | 72.8 | B- | 22.2 | 92.6 | 65.3 | 83.9 | 95.4 | 98.9 | 100.0 | 99.9 | 2,282,480 |
| Django | 67.9 | C+ | 17.8 | 60.6 | 72.0 | 85.5 | 96.6 | 99.9 | 100.0 | 100.0 | 477,491 |
| Excalidraw | 68.9 | C+ | 53.0 | 70.1 | 19.4 | 96.8 | 96.0 | 89.5 | 100.0 | 100.0 | 178,080 |
| gh CLI | 50.1 | D+ | 44.3 | 15.7 | 9.4 | 55.0 | 79.5 | 94.9 | 100.0 | 100.0 | 148,047 |
| Appwrite | 42.4 | D- | 2.5 | 15.9 | 2.6 | 68.6 | 90.3 | 99.5 | 100.0 | 100.0 | 19,168 |
AI-Heavy
| Project | Overall | Grade | Security | Runtime | Testing | Code Smell | Dead Code | Consistency | Duplication | Compliance | LOC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Supabase | 95.5 | A+ | 100.0 | 99.5 | 75.0 | 99.8 | 100.0 | 97.8 | 100.0 | 100.0 | 880,067 |
| Twenty | 85.4 | A- | 100.0 | 70.5 | 53.2 | 90.0 | 100.0 | 93.9 | 100.0 | 100.0 | 1,703,679 |
| NocoDB | 79.2 | B | 61.1 | 65.1 | 71.6 | 94.0 | 95.9 | 98.9 | 100.0 | 99.9 | 429,375 |
| Vinext | 80.0 | B+ | 96.9 | 70.3 | 48.6 | 71.1 | 94.7 | 78.9 | 100.0 | 100.0 | 122,393 |
| LibreChat | 74.9 | B- | 60.5 | 98.2 | 15.4 | 96.7 | 91.3 | 97.5 | 100.0 | 100.0 | 386,671 |
| n8n | 72.6 | B- | 53.6 | 64.7 | 51.6 | 82.0 | 95.5 | 97.9 | 100.0 | 100.0 | 1,752,471 |
| Cal.com | 70.3 | B- | 53.6 | 69.2 | 34.5 | 81.1 | 94.7 | 98.9 | 100.0 | 100.0 | 764,436 |
| Dify | 70.6 | B- | 25.8 | 93.5 | 41.7 | 92.5 | 94.3 | 98.6 | 100.0 | 100.0 | 1,359,080 |
| Bitchat | 69.1 | C+ | 26.9 | 21.9 | 99.1 | 92.8 | 100.0 | 99.9 | 100.0 | 100.0 | 53,496 |
| Open SaaS | 53.3 | D+ | 3.4 | 24.5 | 31.4 | 98.8 | 100.0 | 99.6 | 100.0 | 100.0 | 10,348 |
Group Summary
| Metric | Heritage Avg | AI-Heavy Avg | Delta (H-AI) |
|---|---|---|---|
| Overall | 78.2 | 75.1 | +3.1 |
| Security | 61.2 | 58.2 | +3.1 |
| Runtime | 75.7 | 67.7 | +7.9 |
| Testing | 59.7 | 52.2 | +7.5 |
| Code Smell | 87.8 | 89.9 | -2.1 |
| Dead Code | 95.8 | 96.6 | -0.8 |
| Consistency | 97.2 | 96.2 | +1.0 |
| Duplication | 100.0 | 100.0 | -0.0 |
| Compliance | 100.0 | 100.0 | +0.0 |
Heritage LOC: 10,317,854. AI-heavy LOC: 7,462,016. Active unresolved issues: heritage 16,274, AI-heavy 15,591.
| Category | Heritage Count | Heritage Share | Heritage /100k LOC | AI-Heavy Count | AI-Heavy Share | AI-Heavy /100k LOC |
|---|---|---|---|---|---|---|
| Security | 3,287 | 20.2% | 31.9 | 680 | 4.4% | 9.1 |
| Runtime | 153 | 0.9% | 1.5 | 91 | 0.6% | 1.2 |
| Testing | 6,119 | 37.6% | 59.3 | 8,999 | 57.7% | 120.6 |
| Code Smell | 4,429 | 27.2% | 42.9 | 2,714 | 17.4% | 36.4 |
| Dead Code | 2,010 | 12.4% | 19.5 | 2,788 | 17.9% | 37.4 |
| Consistency | 270 | 1.7% | 2.6 | 312 | 2.0% | 4.2 |
| Duplication | 3 | 0.0% | 0.0 | 1 | 0.0% | 0.0 |
| Compliance | 3 | 0.0% | 0.0 | 6 | 0.0% | 0.1 |
| Severity | Heritage Count | Heritage Share | AI-Heavy Count | AI-Heavy Share |
|---|---|---|---|---|
| Critical | 35 | 0.2% | 35 | 0.2% |
| High | 257 | 1.6% | 211 | 1.4% |
| Medium | 13,525 | 83.1% | 12,592 | 80.8% |
| Low | 2,080 | 12.8% | 2,301 | 14.8% |
| Info | 377 | 2.3% | 452 | 2.9% |
So heritage leads overall, 78.2 to 75.1. A gap of 3.1 points. Heritage is ahead on security, runtime, testing, and consistency. AI-heavy edges it on code smell (+2.1) and dead code (+0.8). But the averages are doing a lot of work to hide what is going on underneath.
Security accounts for 20.2% of heritage issues and just 4.4% of AI-heavy issues. Testing is 37.6% of heritage issues and 57.7% of AI-heavy. Normalize by codebase size and the split gets sharper: AI-heavy projects carry about 2.0x the testing issue density (120.6 vs 59.3 per 100k LOC) and about 1.9x the dead-code density (37.4 vs 19.5 per 100k LOC). Heritage carries about 3.5x the security issue density (31.9 vs 9.1 per 100k LOC).
That 3.1-point gap is smaller than the difference in where the debt concentrates. Heritage loses points in fewer but heavier categories -- its security volume is skewed by large, mostly medium-severity platform debt in Kubernetes and framework-surface debt in Django. AI-heavy loses points more evenly: most of the weaker projects share the same combination of thin verification, partially integrated code, and missing operational controls. The averages land close together because the two groups are paying different taxes.
Security
Heritage security debt comes in two shapes that raw counts blur together.
The first is broad, mostly medium-severity platform exposure. Kubernetes contributes 2,210 security issues, but that inventory breaks down to 2 high, 2,207 medium, and 1 low. It dominates raw count without being the main source of critical or high-severity pressure. The second shape is concentrated boundary failure in smaller or more feature-exposed surfaces: Appwrite has 13 critical/high security issues out of 25 total security issues, Mattermost has 36 out of 106, Grafana has 20 out of 202, and Django has 19 out of 654. Heritage has far more security issues overall than AI-heavy (3,287 vs 680), but AI-heavy has more critical/high security issues (154 vs 113).
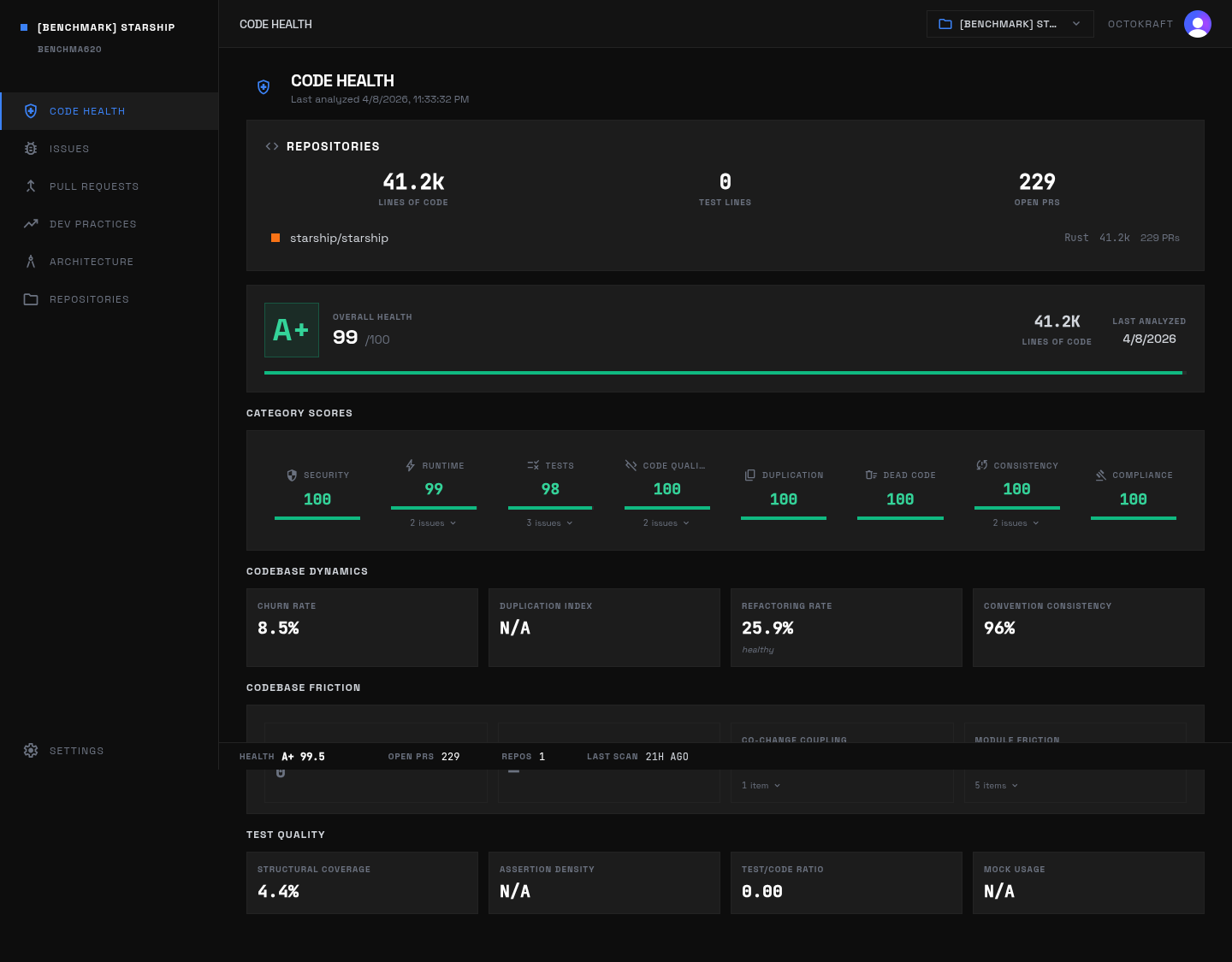
Starship's health dashboard: 99.5 overall with perfect security, 99.8 code quality, and 99.5 runtime safety across 41K lines of Rust.
AI-heavy security debt is smaller by share but packed tighter around feature-boundary logic. Dify contributes 570 security issues, and unlike Kubernetes its inventory carries real severity concentration: 102 are high. NocoDB has 12 high-severity security issues out of 28 total security findings, Cal.com has 12 critical/high out of 29, n8n has 11 critical/high out of 17, and Open SaaS has 5 critical/high out of 11. Open SaaS and Appwrite show the same failure mode in different codebases: authorization and input-validation gaps sitting directly on endpoint and integration paths. In the AI-heavy group, the common examples are missing authorization on file download URLs and webhooks in Open SaaS, missing auth tag handling and unsafe HTML rendering paths in Cal.com, and insecure hashing, SQL text usage, or frame/header handling in Dify.
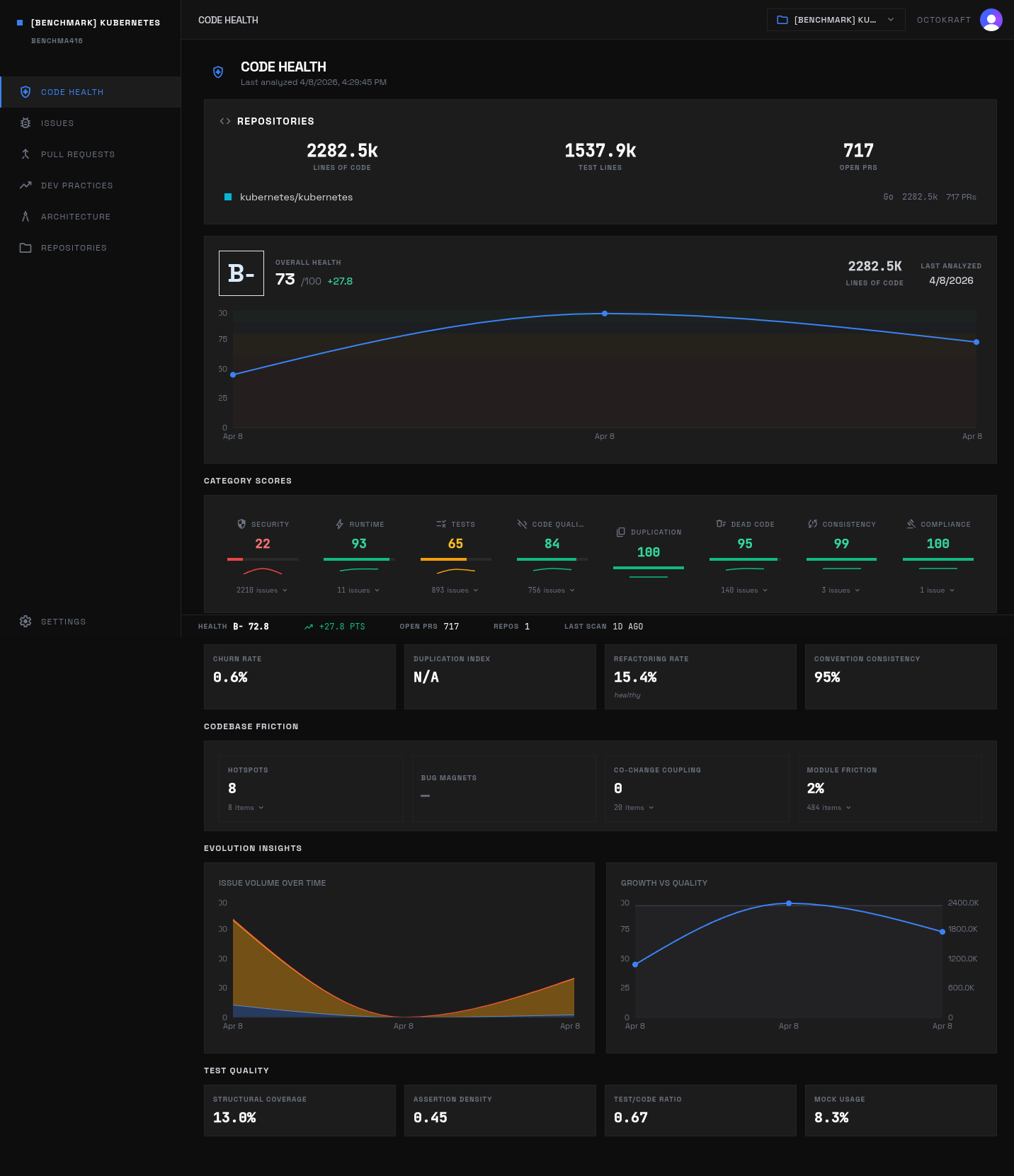
Kubernetes scores B- overall (72.8) with security at 22.2. Most of the 2,210 security findings are medium-severity.
Specific issue-table examples:
- Heritage:
Missing authorization on database bulk update endpointin Appwrite,Database connection shared statein Django,Path traversal in source map processingin Grafana, andSSRF vulnerability in API route revalidate via Host header manipulationin Next.js. - AI-heavy:
Missing authorization in file download URL generationandMissing webhook idempotency protectionin Open SaaS,Calendar API Rate Limitingand unsafe HTML rendering paths in Cal.com, and repeated MD5 and SQL-text findings in Dify.
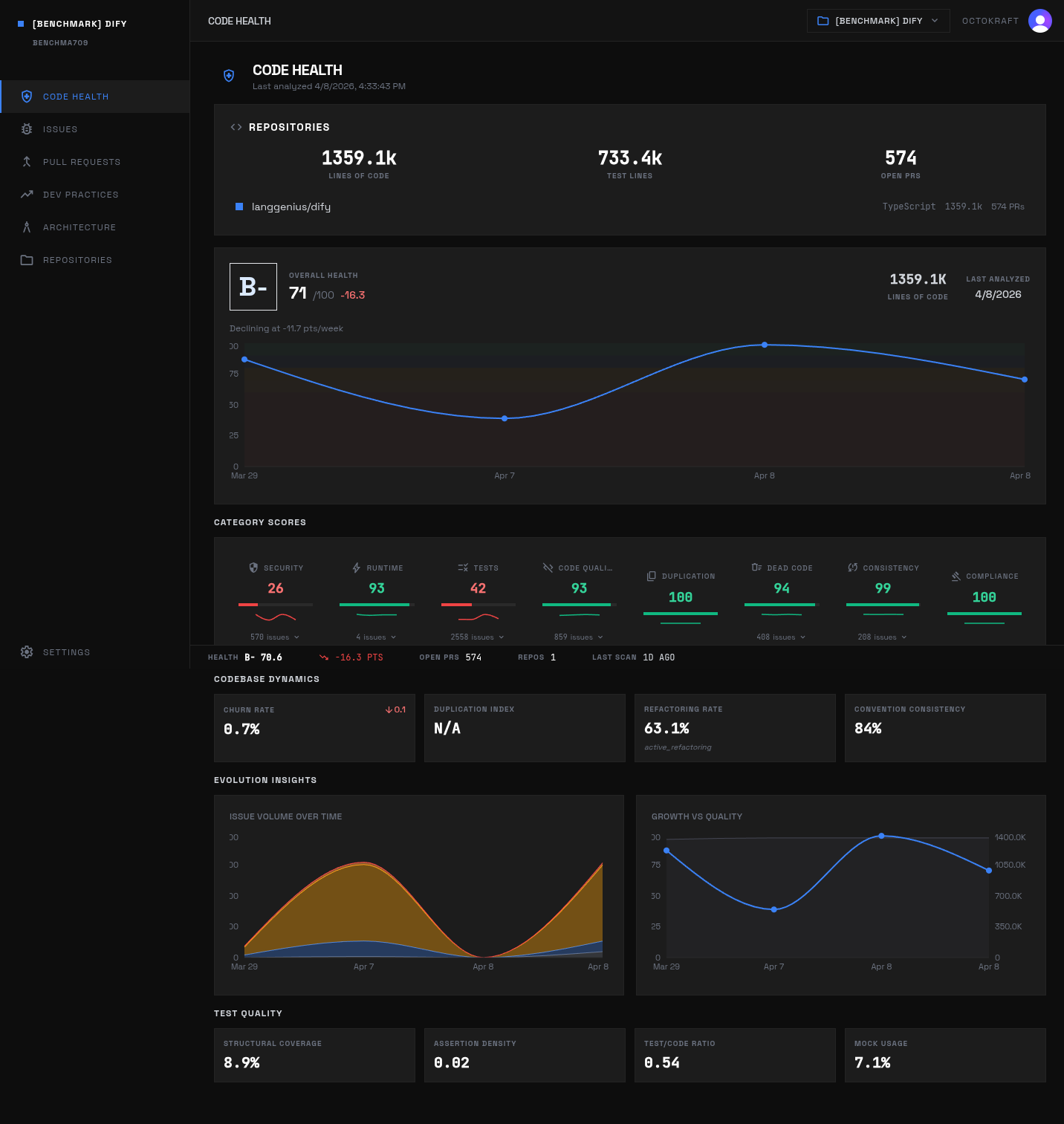
Dify at B- (70.6): security scores 25.8 with 102 high-severity findings across 1.4M lines of Python and TypeScript.
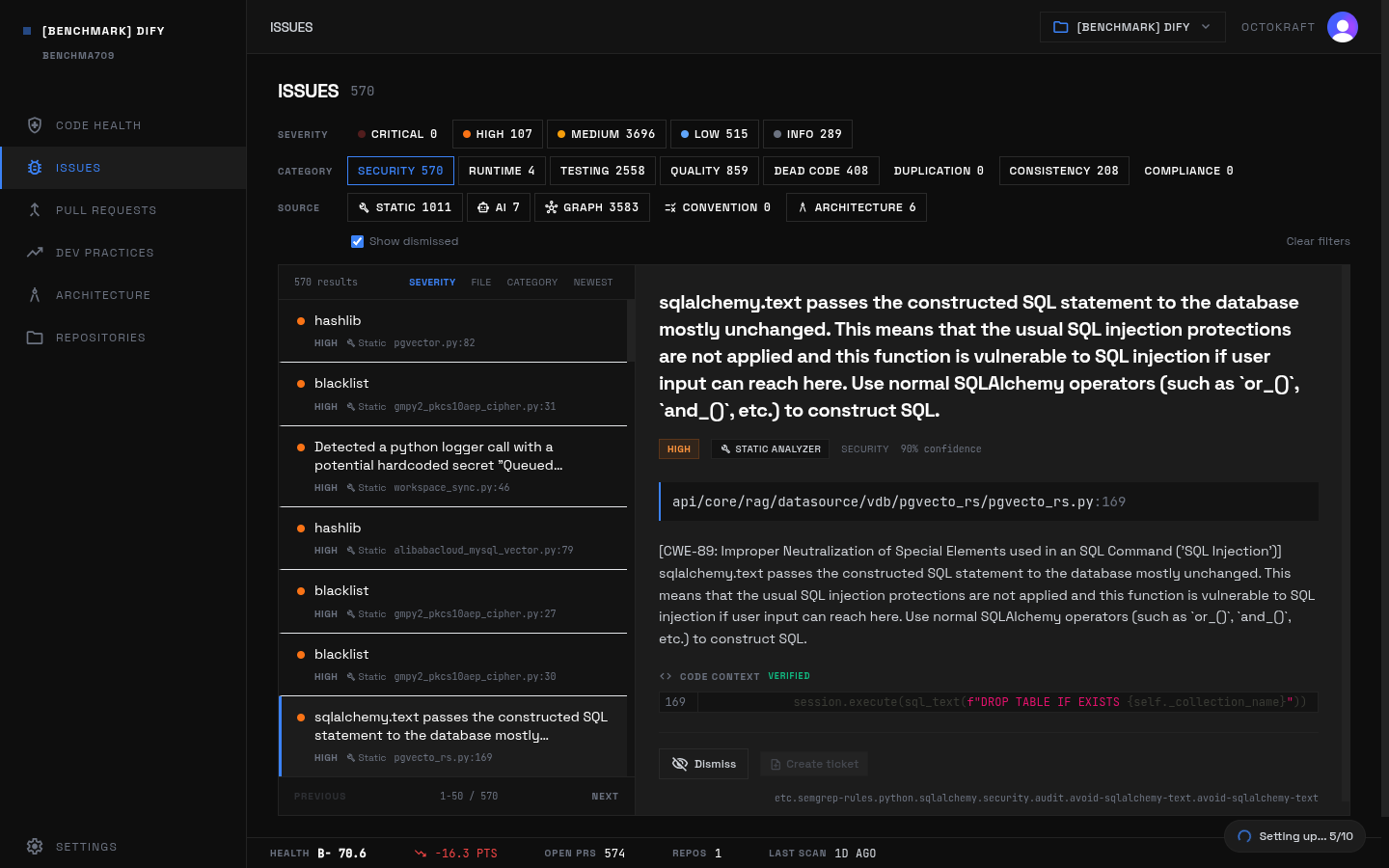
Dify security detail: SQL injection findings in the workflow persistence layer.
Reading the issue descriptions side by side makes the similarity between groups clearer -- and the differences more specific. Kubernetes is better understood as a scale outlier than a template for the heritage group's security profile. Its findings are overwhelmingly repeated medium-severity unsafe, weak-randomness, and TLS-boundary issues that come from low-level systems work close to kernel, network, and serialization edges. The more severity-concentrated heritage examples live elsewhere: Django repeatedly hits as_sql, mark_safe, template-link, and redirect patterns because the framework exposes extension points for query construction and HTML rendering; Grafana and Mattermost accumulate file, plugin, and request-routing boundary failures; Appwrite collapses on central missing-authorization paths.
The AI-heavy security descriptions cluster differently. The repeated patterns are trust-boundary shortcuts: missing ownership checks in Open SaaS signed URL generation, missing webhook idempotency, dangerouslySetInnerHTML in Cal.com, no-op or absent rate limiting in NocoDB, user-controlled CORS or command execution in n8n, and string-built SQL plus header-control issues in Dify. These are not framework-extension problems. They are feature implementation problems where the happy path shipped but the adversarial path is only partially modeled.
There is also a size effect. Small repos get penalized for concentrated failures; large repos get penalized for surface area. Appwrite has only 25 active security issues, but 13 are critical or high and several sit on central authorization paths, so the score collapses to 2.5. Kubernetes has 2,210 security issues, but only 2 are high and none are critical, so the score collapses for the opposite reason: not one catastrophic subsystem, but massive persistent medium-severity exposure across low-level code. The same count can mean very different things depending on whether the descriptions point to repeated central boundary failures or repeated broad-surface policy violations.
Testing
Testing is the largest category for both groups. In the AI-heavy set, it is dominant. Heritage projects carry 6,119 testing issues (37.6% of group total). AI-heavy projects carry 8,999 testing issues (57.7%). The issue counts and test metrics point to a difference in failure mode: heritage projects more often have deep but uneven test coverage around complex subsystems, while AI-heavy projects more often have broad feature surface with weak assertions, skipped suites, or missing tests on critical paths.
| Project | Testing Score | Test LOC | Test Ratio | Structural Cov. | Mock Usage | Assertion Density |
|---|---|---|---|---|---|---|
| Terraform | 99.4 | 313,521 | 68.7% | 40.6% | 9.3% | 0.501 |
| Traefik | 98.9 | 122,728 | 75.2% | 3.6% | 0.0% | 0.000 |
| Next.js | 74.8 | 509,843 | 27.8% | 12.6% | 2.1% | 0.084 |
| Prometheus | 26.0 | 177,769 | 60.9% | 12.0% | 0.0% | 0.298 |
| gh CLI | 9.4 | 116,104 | 78.4% | 46.2% | 28.2% | 0.563 |
| Appwrite | 2.6 | 108,837 | 567.8% | 0.0% | 0.0% | 0.000 |
| Twenty | 53.2 | 261,094 | 15.3% | 1.8% | 4.7% | 0.017 |
| LibreChat | 15.4 | 178,479 | 46.2% | 12.6% | 19.0% | 0.060 |
| Dify | 41.7 | 733,357 | 54.0% | 8.9% | 7.1% | 0.024 |
| Cal.com | 34.5 | 192,653 | 25.2% | 12.0% | 17.9% | 0.311 |
The highest-impact testing examples cluster in a handful of projects. Heritage: Mock verifier returns fake results without verification and Unit tests bypass all cryptographic verification with mocks in gh CLI; Notifier lacks retry mechanism and retry tests and Storage interfaces lack contract tests in Prometheus; Vector operations completely untested and Collaboration tests bypass real logic with mocks in Excalidraw. AI-heavy: all three workflow E2E suites are commented out in Twenty, the Confirm Handler suite is skipped in Cal.com, and LibreChat has NO tests for data-service.ts, NO tests for request/auth layer, and waitFor calls without await in login tests.
Test volume does not map to verification quality -- not even close. gh CLI has a 78.4% test-code ratio and 46.2% structural coverage but still scores 9.4 because the open issues are concentrated in mock-heavy verification failures. Appwrite has test LOC far above production LOC and still scores 2.6 because critical flows remain unverified. Terraform and Traefik score above 98 because their open testing debt is narrow and their high-value paths are much better covered.
Dig into the descriptions and testing debt splits into three recurring forms.
First, breadth debt: huge numbers of Untested Function, Untested Method, or no test callers findings across Next.js, Grafana, Mattermost, Kubernetes, Cal.com, n8n, Dify, NocoDB, and Appwrite. These are not about one missing suite. They describe platforms where the exported or callable surface grew faster than direct verification. In the largest TypeScript-heavy repos, this is why testing becomes the dominant category by raw count.
Second, false-confidence debt. The descriptions for gh CLI, Supabase, Starship, Django, NocoDB, n8n, Dify, and Mattermost all include low assertion density or tests that exercise code paths without verifying outcomes. The severe examples are sharper: gh CLI's mock verifier returns fabricated results, Appwrite health tests only check HTTP 200 instead of service connectivity, Excalidraw has a test asserting the wrong variable, and LibreChat uses waitFor without await. These are not missing tests. They are tests that can stay green while core behavior regresses.
Third, disabled-critical-path debt. Twenty has workflow and auth tests commented out. Cal.com skips the Confirm Handler suite. Deno leaves SIGINT coverage ignored. Prometheus lacks notifier retry and storage contract tests. LibreChat has no tests for its main data-service and request/auth layers. The lowest testing scores come from this same structural problem: the missing or weak tests sit on the control paths that move state across boundaries, not on leaf helpers.
That is why the score shape diverges so sharply between projects with superficially similar test footprints. Traefik's low assertion density does not hurt much because the unresolved descriptions do not point to broken confidence on central behavior. gh CLI and Appwrite are the opposite: they have plenty of test artifacts, but those artifacts do not protect the code paths that matter most.
Code Smell
Heritage projects carry more code-smell volume both in raw count (4,429 vs 2,714) and density (42.9 vs 36.4 per 100k LOC). The dominant heritage smell patterns are oversized framework and controller modules, shared configuration surfaces, and cross-package coupling: app-render.tsx God Module in Next.js, controller-heavy classes across Kubernetes, Provider protocol evolution and deep configuration logic in Terraform, and large plugin, storage, or UI support classes in Mattermost.
AI-heavy code smell issues are less dominant by share, but the bottom-end scores point to a different structural pattern: oversized generated entrypoints and boundary violations. Vinext is the clearest case (God Module: index.ts (4210 lines, 62 imports) and Circular Dependencies: shims/ to server/). Cal.com is driven by Features Importing from tRPC and Layer Boundary Violations. n8n combines high-volume untested execute paths with platform-level structural findings like God class: TestRunnerService and global state issues. Dify adds broad service-layer complexity across both Python and TypeScript.
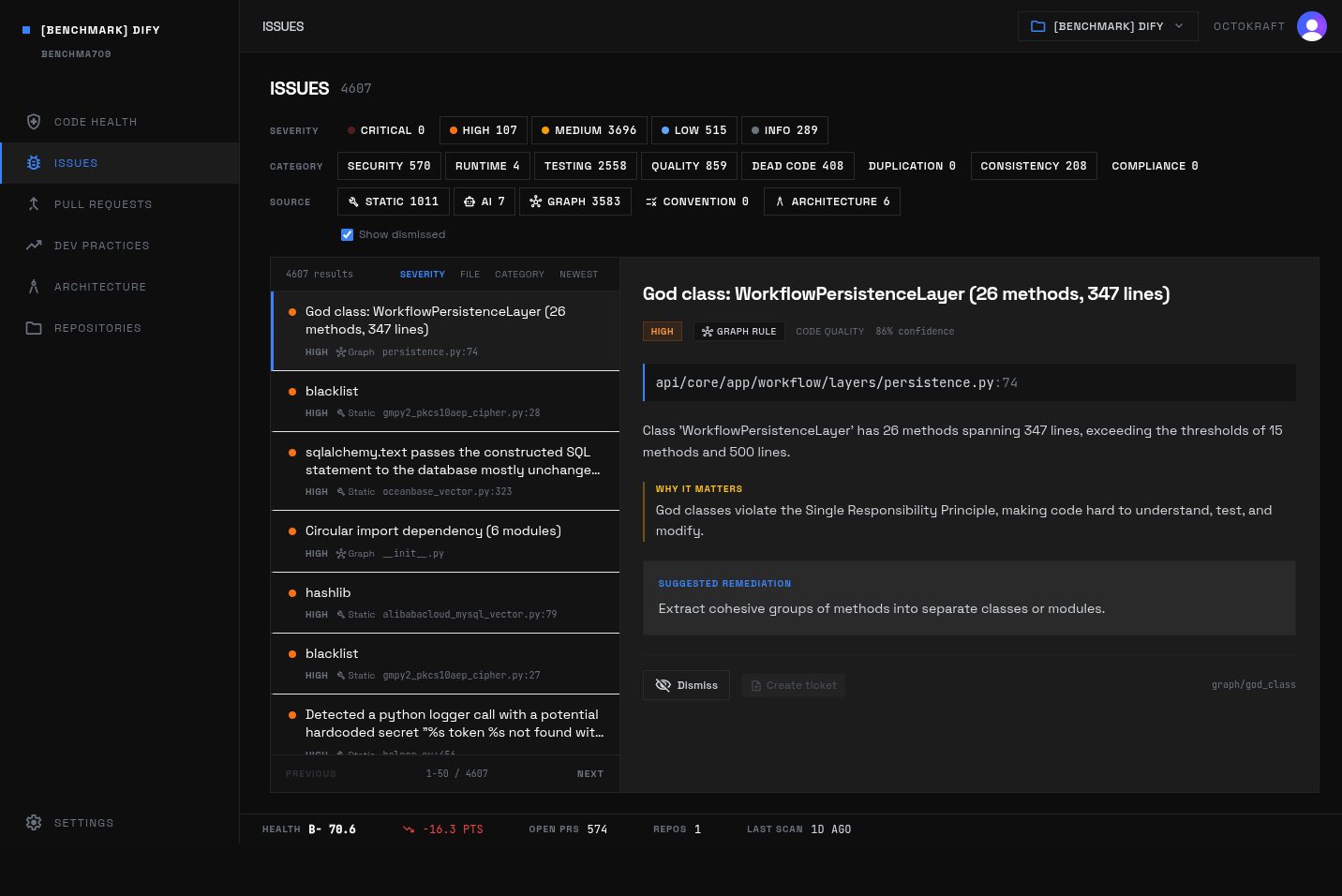
Dify's WorkflowPersistenceLayer flagged as a god class, one of the structural anti-patterns measured in code quality scoring.
This category is about change cost, not immediate exploitability. Heritage smells mainly indicate long-lived modules that accumulated responsibilities. AI-heavy smells more often indicate architecture that arrived monolithic, with boundaries added later or not enforced consistently.
Two strong similarities run across both groups. The first is centralization. Starship's Context becomes a god object. Terraform's Context and backend abstractions mix planning, execution, and state responsibilities. Next.js carries app-render.tsx and singleton state. Grafana, Kubernetes, gh CLI, Supabase, Twenty, n8n, and Vinext all have the same pattern at different scales: one file or service grows until it becomes the coordination point for unrelated concerns. Code-smell counts rise because change impact stops being local.
The second is boundary leakage. Traefik's providers all depend on dynamic config. Prometheus storage interfaces leak into indexing and query paths. Supabase interface modules import one another directly. Cal.com features import from trpc. NocoDB backend code reaches into GUI helpers. Open SaaS payment code depends on user code. Vinext shims import server implementation details. All of these point to the same structural outcome: the module graph stops representing product boundaries cleanly, so any change to one subsystem propagates farther than expected.
The difference between heritage and AI-heavy code smell is mostly how the structure got there. In heritage repos the descriptions read like accumulated coordination burden: protocol evolution, config hubs, registry layers, large controllers, and years of backfilled responsibilities. In AI-heavy repos the descriptions read more like initial over-aggregation: one adapter, one dataloader, one plugin file, one shim layer, one repository with too many methods. Both produce the same maintenance penalty. They just imply different histories.
Dead Code
Dead-code volume is where AI-heavy projects separate most from heritage after testing. Heritage carries 2,010 dead-code issues (12.4% of its issue set, 19.5 per 100k LOC). AI-heavy carries 2,788 (17.9%, 37.4 per 100k LOC). The largest contributors are n8n (1,085), Cal.com (607), Dify (408), LibreChat (344), and NocoDB (310).
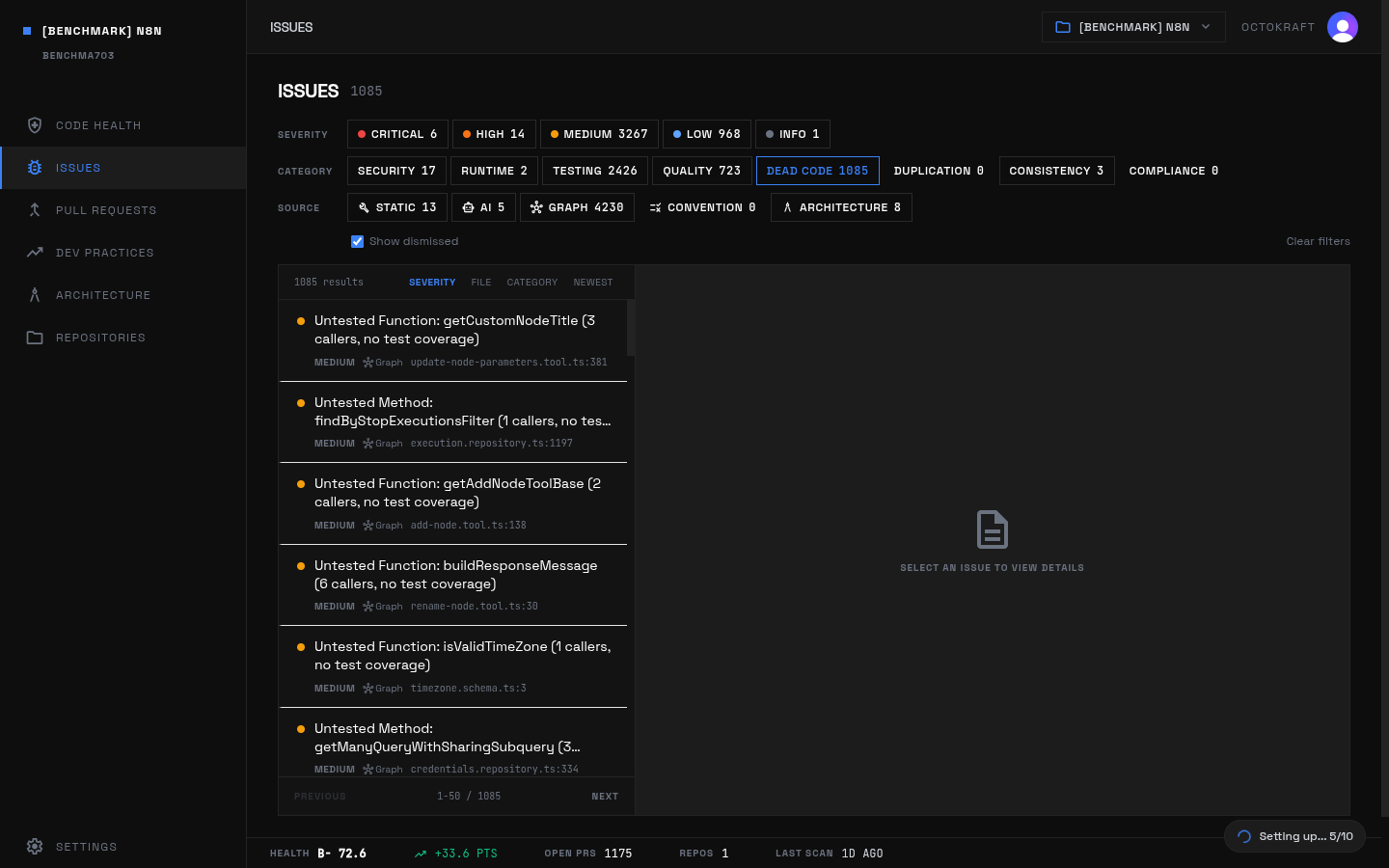
n8n's dead code panel: 1,085 issues, the highest count in the benchmark. Unreferenced variables, constants, and entire exported functions across 1.75M lines.
The issue titles show a pattern of partially retained feature and integration scaffolding. In n8n, unreferenced variables like descriptions, eventFields, and xmlFileInfo repeat across node packages. In Cal.com, unused handler constants and request-method exports (POST, GET) accumulate around route handlers. LibreChat has unused service-layer imports and wrapper variables. Heritage dead code, by contrast, is more evenly distributed across large mature codebases -- Grafana (495), Mattermost (380), Next.js (344), and Deno (351) -- where the open inventory looks more like maintenance residue inside older modules and APIs.
Two distinct dead-code families show up in the descriptions. One is stale scaffolding: unreferenced config symbols, unused loader variables, leftover request handlers, and dormant exports. Cal.com, n8n, Dify, LibreChat, and parts of Next.js fit this pattern. The recurring descriptions are Unreferenced Variable, Unreferenced Constant, and small utility or route-handler functions that remain in place after a feature or integration changed shape.
The other family is half-alive code: functions and methods that still have callers in production graphs but are effectively orphaned from verification or clear ownership. Deno, Mattermost, Kubernetes, NocoDB, and Excalidraw show this pattern through dead-code findings that are high-fan-out or untested callable functions. Maintenance residue here is not just unused artifacts. It is also code that remains technically connected but operationally under-maintained.
The same dead-code count can imply very different cleanup costs. Django's dead code is dominated by locale constants and long-tail formatting symbols -- mostly maintenance noise. n8n's and Cal.com's dead code sits in integration, handler, and node-definition surfaces, which means the residue is closer to feature behavior and more likely to confuse future changes.
Runtime
Runtime issue counts are small in both groups, but they carry outsized leverage because they sit on concurrency, resource management, and failure-handling paths. Heritage runtime average is 75.7 versus 67.7 for AI-heavy. The lowest heritage scores are gh CLI (15.7), Appwrite (15.9), and Django (60.6). The lowest AI-heavy scores are Bitchat (21.9), Open SaaS (24.5), n8n (64.7), and NocoDB (65.1).
Heritage runtime issues concentrate in complex mature execution paths: state upgrades and provisioners in Terraform, invalidation and aggregation in Next.js, shared database lifecycle in Django, and global shared state in gh CLI. AI-heavy runtime issues concentrate in missing operational controls: connection exhaustion, rate limiting, memory leaks, silent fallbacks, and missing timeouts. Examples include Database connection exhaustion under load and Memory leak in job results map in n8n, Rate limiting not implemented in NocoDB, No Timeout for Route Handler Execution in Vinext, and unbounded queries plus TOCTOU credit updates in Open SaaS.
The descriptions across both groups are less about business logic and more about lifecycle control. The repeated motifs are unbounded growth, missing cleanup, and hidden shared state. Next.js stores debug and error streams in global maps without cleanup timeouts. Deno lacks request-body size limits in its HTTP layer. Prometheus warns about high-cardinality memory growth. n8n leaves job results in an unbounded map and ships with a critically small default DB pool. Dify exposes webhook endpoints without rate limiting. Open SaaS has unbounded queries and no cache layer. Bitchat lacks backpressure and has concurrent access to shared BLE state.
A second motif is asynchronous work without clear ownership. Terraform discards cancel functions and can log but continue after malformed state upgrade paths. Traefik has global connection state and goroutine management concerns. Grafana spawns background goroutines without completion tracking. gh CLI caches config and auth state in unsynchronized globals. LibreChat caches stream runtime state that can race across subscribers. Vinext returns detached request contexts and has no timeout on route execution. All of these point to the same operational weakness: async state exists longer, or in more places, than the code acknowledges explicitly.
A repo can have only a handful of runtime issues and still score badly if those issues sit on resource control, concurrency, or request lifecycle boundaries. Runtime here is a category of leverage, not volume.
Consistency
Consistency is high across almost the entire set. Heritage averages 97.2 and AI-heavy 96.2. The main outlier is Vinext at 78.9. Excalidraw (89.5), scikit-learn (91.3), Deno (93.8), and Twenty (93.9) are the other projects materially below the pack. In those cases the issue titles point less to naming or formatting drift and more to architectural alignment problems: oversized central modules, wide blast-radius utility layers, or large shim files that mix abstractions.
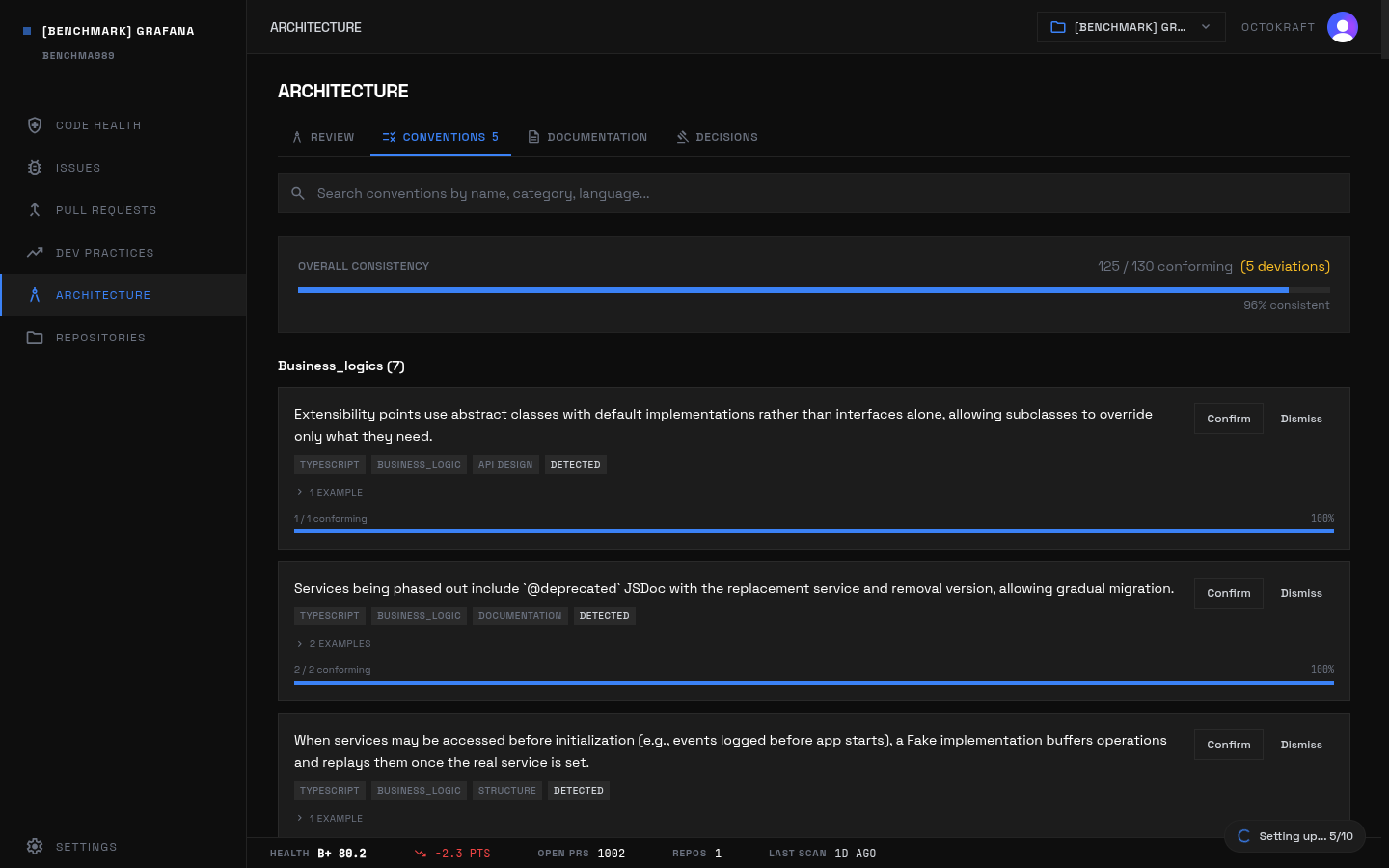
Grafana's conventions panel: 96.2% convention adherence and 99.9 consistency score across 2.12M lines.
Low volume, but specific signal. A project can have near-perfect lint and style consistency while still losing points on cross-module structure. Vinext is the clearest example: convention adherence remains high enough to keep most files uniform, but the active issues show that the framework core does not maintain clean dependency direction between entrypoint, shim, and server layers.
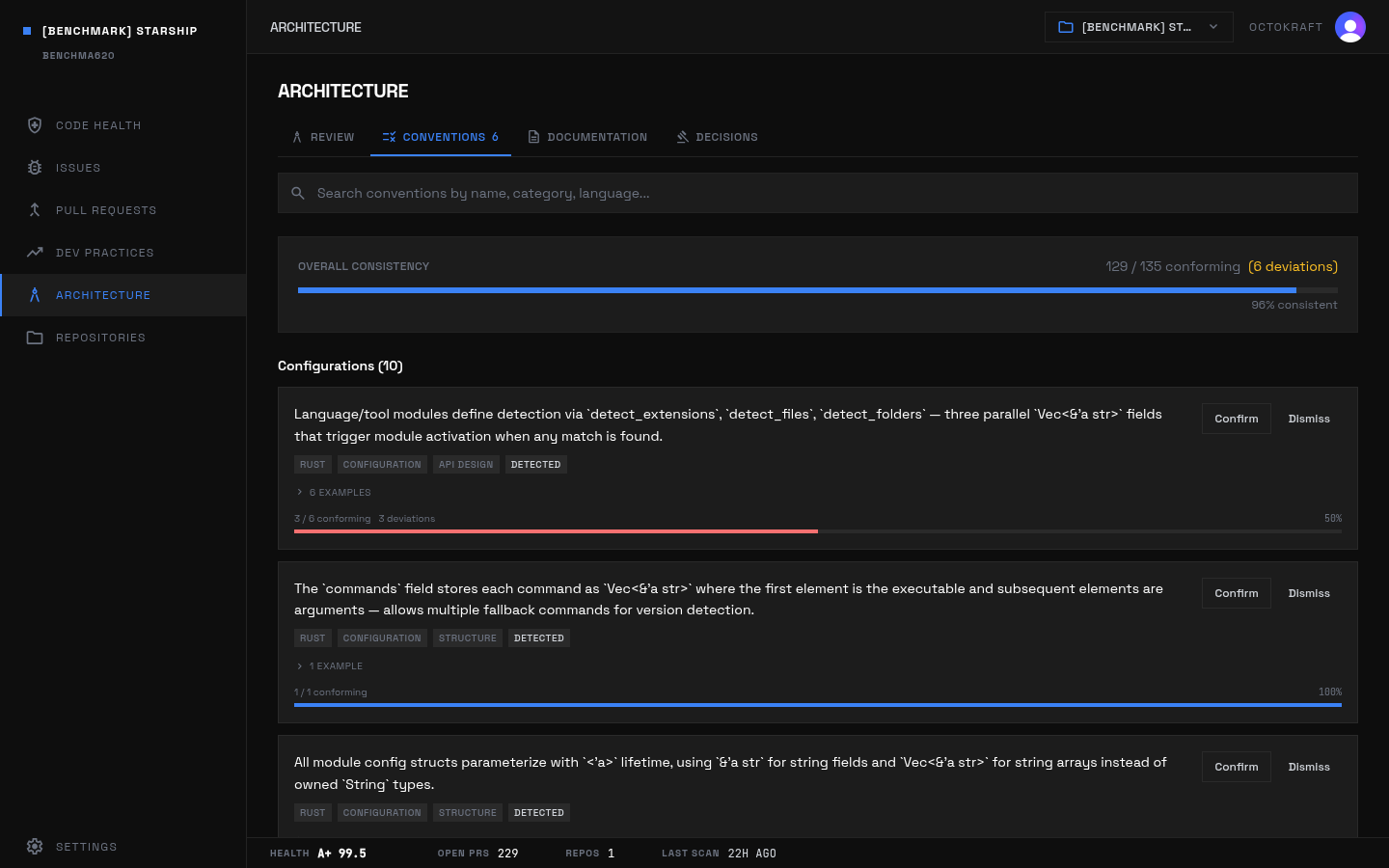
Starship's conventions: 95.6% adherence with only 6 deviations across the entire 41K-line Rust codebase.
In large TypeScript-heavy projects like Mattermost, Dify, and LibreChat, many consistency findings are surface-level pattern drift: optional-chain suggestions, implicit any, unnecessary fragments, or inconsistent response/version handling. Those can produce high counts without destroying the score because they do not change the codebase's architecture.
In smaller or more central-framework repos, the consistency descriptions are architectural. Deno's resolver crosses layer boundaries. Next.js concentrates rendering in one 7,502-line module. scikit-learn's utils layer creates wide blast-radius coupling. Excalidraw's App.tsx centralizes too much behavior. Twenty's dataloader service becomes the integration point for unrelated concerns. Vinext's shims stop being shims and start carrying implementation logic. A repo can have only a few consistency issues and still lose far more points than a larger repo with hundreds of style-level nits.
Consistency count alone is misleading. Mattermost has 221 consistency issues and still scores 99.0 because the descriptions are mostly low-level language and lint drift. Vinext has only 8 consistency issues and scores 78.9 because the descriptions point to broken architectural expectations in the files that define the whole framework.
Duplication and Compliance
These two categories do not differentiate the 24 projects. Duplication contributes only four active issues across the entire set: Terraform has the only score below 100.0 (99.9), and every other included project is effectively perfect. Compliance contributes nine active issues total, split between the groups with no meaningful score movement. For this data slice, copy-paste duplication and declared-standard compliance are not where health variance comes from.
Project Profiles
Heritage
Starship
Scores: overall 99.5 (A+), security 100.0, runtime 99.5, testing 97.8, code smell 99.8, dead code 100.0, consistency 99.8, duplication 100.0, compliance 100.0.
Active unresolved issues: 12. Severity mix: medium 4, low 8. Largest categories: Runtime 3, Testing 3, Code Smell 3, Consistency 2, Security 1.
Twelve issues. That is the entire open inventory for a 41k-LOC Rust prompt. No single weak subsystem; the remaining items are narrow test and coupling gaps in otherwise stable code paths.
Examples from analysis_issues:
- Command Execution on Hot Path (
src/modules/rust.rs) - Git Operations Complexity (
src/modules/git_status.rs) - No tests for parallel computation (rayon par_iter) (
src/print.rs)
Traefik
Scores: overall 97.9 (A+), security 100.0, runtime 96.6, testing 98.9, code smell 88.3, dead code 100.0, consistency 99.7, duplication 100.0, compliance 100.0.
Active unresolved issues: 17. Severity mix: critical 1, high 3, medium 7, low 6. Largest categories: Consistency 6, Runtime 4, Code Smell 3, Testing 2, Security 1, Compliance 1.
The open set is structural rather than volumetric. The repo is mostly clean, and the remaining items point to shared configuration and provider coupling rather than broad quality debt.
Examples from analysis_issues:
- Non-existent lodash version 4.18.1 creates supply chain attack risk (
webui/package.json) - API Package Change Impact (
pkg/api/) - @types/lodash version lag with runtime lodash 4.18.1 (
webui/package.json)
Terraform
Scores: overall 92.7 (A), security 93.1, runtime 70.3, testing 99.4, code smell 95.4, dead code 100.0, consistency 99.8, duplication 99.9, compliance 100.0.
Active unresolved issues: 44. Severity mix: high 7, medium 31, low 5, info 1. Largest categories: Runtime 22, Security 8, Code Smell 7, Consistency 5, Testing 1, Duplication 1.
The dominant risk sits in mutable infrastructure state and provisioner execution paths. Testing is strong; what remains is concentrated in failure handling and operational correctness.
Examples from analysis_issues:
- Error Logged But Not Returned After State Upgrade Failure (
internal/terraform/upgrade_resource_state.go) - Goroutine Leak in local-exec Provisioner (
internal/builtin/provisioners/local-exec/resource_provisioner.go) - Deeply Nested Conditional Logic in Configure (
internal/cloud/backend.go)
Deno
Scores: overall 90.6 (A), security 84.2, runtime 97.9, testing 81.6, code smell 89.3, dead code 93.7, consistency 93.8, duplication 100.0, compliance 100.0.
Active unresolved issues: 911. Severity mix: critical 1, high 14, medium 821, low 74, info 1. Largest categories: Code Smell 390, Dead Code 351, Testing 144, Security 13, Runtime 10, Consistency 3.
Nine hundred and eleven issues, but the score still lands at 90.6 because the severity skews medium and the debt is spread across extensions and runtime bindings rather than concentrated on critical paths.
Examples from analysis_issues:
- Resolver Coupling (
libs/resolver/lib.rs) - Critical SIGINT handling test marked as ignored (
tests/integration/test_tests.rs) - LSP Heavy Dependencies (
cli/lsp/language_server.rs)
Next.js
Scores: overall 87.8 (A-), security 91.7, runtime 72.5, testing 74.8, code smell 93.6, dead code 98.2, consistency 94.7, duplication 100.0, compliance 100.0.
Active unresolved issues: 2,070. Severity mix: critical 2, high 8, medium 1,812, low 248. Largest categories: Testing 967, Code Smell 724, Dead Code 344, Runtime 20, Security 12, Consistency 3.
Most of the active debt lives inside framework internals, not application edges. Testing, structure, and a small number of high-impact runtime and security issues concentrate in rendering and turbopack paths.
Examples from analysis_issues:
- Unbounded Graph Traversal During Invalidation (
turbopack/crates/turbo-tasks-backend/src/backend/operation/aggregation...) - app-render.tsx God Module (
packages/next/src/server/app-render/app-render.tsx) - SSRF vulnerability in API route revalidate via Host header manipulation (
packages/next/src/server/api-utils/node/api-resolver.ts)
Prometheus
Scores: overall 85.2 (A-), security 100.0, runtime 90.2, testing 26.0, code smell 95.2, dead code 100.0, consistency 99.8, duplication 100.0, compliance 100.0.
Active unresolved issues: 19. Severity mix: critical 2, high 7, medium 5, low 4, info 1. Largest categories: Testing 10, Consistency 4, Code Smell 3, Runtime 1, Duplication 1.
Nineteen issues total. Low volume. But key notifier and storage behaviors still lack direct verification -- the testing score of 26.0 comes from missing contract and retry coverage, not from broad code quality problems.
Examples from analysis_issues:
- Notifier lacks retry mechanism and retry tests (
notifier/manager.go) - Storage interfaces lack contract tests (
storage/interface.go) - Fanout storage lacks concurrent access tests (
storage/fanout_test.go)
Grafana
Scores: overall 80.2 (B+), security 50.6, runtime 93.3, testing 65.3, code smell 90.6, dead code 95.3, consistency 99.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 3,136. Severity mix: critical 1, high 34, medium 2,781, low 319, info 1. Largest categories: Testing 1,724, Code Smell 706, Dead Code 495, Security 202, Runtime 7, Consistency 2.
At 2.1 million lines of code, the issue mix mostly reflects scale. Testing, code smell, and dead code dominate by count, while the highest-impact security items sit in request and file-handling surfaces.
Examples from analysis_issues:
- Path traversal in source map processing (
pkg/api/frontendlogging/source_maps.go) - God class: ProvisioningApiHandler (31 methods, 2 lines) (
pkg/services/ngalert/api/provisioning.go) - God class: AlertRuleMutators (55 methods, 1 lines) (
pkg/services/ngalert/models/testing.go)
Mattermost
Scores: overall 79.4 (B), security 43.5, runtime 99.1, testing 64.4, code smell 89.8, dead code 96.8, consistency 99.0, duplication 100.0, compliance 100.0.
Active unresolved issues: 3,145. Severity mix: critical 1, high 51, medium 1,951, low 810, info 332. Largest categories: Testing 1,267, Code Smell 1,168, Dead Code 380, Consistency 221, Security 106, Runtime 3.
A large maintenance surface: many testing and structural issues, plus a smaller but meaningful security tail in plugin and file-handling code.
Examples from analysis_issues:
Cleanis not intended to sanitize against path traversal attacks (server/channels/app/plugin_requests.go)- Data Loss Bug in LocalResponseWriter.Write (
server/channels/app/integration_action.go) - God class: DriverImpl (23 methods, 10 lines) (
server/channels/app/plugin_db_driver.go)
scikit-learn
Scores: overall 79.2 (B), security 54.5, runtime 85.0, testing 59.1, code smell 97.6, dead code 100.0, consistency 91.3, duplication 100.0, compliance 100.0.
Active unresolved issues: 43. Severity mix: critical 1, high 14, medium 16, low 12. Largest categories: Security 16, Runtime 16, Code Smell 8, Consistency 3.
Forty-three issues. Low total count. But the open issues land in native-code, deserialization, and parallelism paths -- the kind of places where a single issue can take a process down.
Examples from analysis_issues:
- Integer overflow in buffer size calculation (
sklearn/tree/_partitioner.pyx) - Missing null check after malloc in parallel regions (
sklearn/cluster/_k_means_minibatch.pyx) - Joblib deserialization vulnerability in dataset loading (
sklearn/datasets/_rcv1.py)
Kubernetes
Scores: overall 72.8 (B-), security 22.2, runtime 92.6, testing 65.3, code smell 83.9, dead code 95.4, consistency 98.9, duplication 100.0, compliance 99.9.
Active unresolved issues: 4,017. Severity mix: high 50, medium 3,706, low 260, info 1. Largest categories: Security 2,210, Testing 894, Code Smell 756, Dead Code 140, Runtime 12, Consistency 3.
Security volume dominates because the codebase exposes low-level system and networking surfaces at 2.3 million lines of code. The rest of the debt sits in controller-heavy testing and structural hotspots.
Examples from analysis_issues:
- Using the unsafe package in Go gives you low-level memory management... (
cmd/kubeadm/app/apis/kubeadm/v1beta3/zz_generated.conversion.go) - Found an insecure gRPC server without
grpc.Creds()or options with credentials (pkg/kubelet/pluginmanager/pluginwatcher/example_plugin.go) - ServiceAccount controller missing all error scenario tests (
pkg/controller/serviceaccount/serviceaccounts_controller_test.go)
Django
Scores: overall 67.9 (C+), security 17.8, runtime 60.6, testing 72.0, code smell 85.5, dead code 96.6, consistency 99.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 1,272. Severity mix: critical 1, high 27, medium 949, low 257, info 38. Largest categories: Security 654, Code Smell 272, Testing 192, Dead Code 145, Runtime 7, Consistency 2.
Security drives the profile. Most of the open debt is attached to query construction, HTML rendering, and redirect surfaces -- the extension points that a 20-year-old web framework hands to every developer who uses it.
Examples from analysis_issues:
- Database connection shared state (
django/db/backends/base/base.py) - Data from request (redirect_url) is passed to redirect(). This is an open redirect and could be exploited (
django/contrib/admin/options.py) - App registry initialization order (
django/apps/registry.py)
Excalidraw
Scores: overall 68.9 (C+), security 53.0, runtime 70.1, testing 19.4, code smell 96.8, dead code 96.0, consistency 89.5, duplication 100.0, compliance 100.0.
Active unresolved issues: 480. Severity mix: critical 4, high 18, medium 414, low 42, info 2. Largest categories: Testing 316, Dead Code 87, Security 26, Runtime 23, Code Smell 19, Consistency 8.
The low overall score comes from verification gaps around drawing math and collaboration paths. The issue mix is not broad -- it is concentrated in core behavior that lacks durable tests.
Examples from analysis_issues:
- Vector operations completely untested (
packages/excalidraw/math/vector.ts) - Collaboration tests bypass real logic with mocks (
excalidraw-app/tests/collaboration/) - Bug in test assertion - tests wrong variable (
packages/excalidraw/points.test.ts)
gh CLI
Scores: overall 50.1 (D+), security 44.3, runtime 15.7, testing 9.4, code smell 55.0, dead code 79.5, consistency 94.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 320. Severity mix: critical 6, high 11, medium 286, low 17. Largest categories: Code Smell 156, Testing 94, Dead Code 39, Runtime 14, Security 13, Consistency 4.
This is a density problem, not a size problem. At 148k LOC, runtime, testing, and structural issues are concentrated in shared CLI plumbing, mocked verification paths, and command-layer coupling.
Examples from analysis_issues:
- God module: pkg/cmd/pr/shared/ (
pkg/cmd/pr/shared/finder.go) - Mock verifier returns fake results without verification (
verification/mock_verifier.go) - Global SSO Header Variable - Data Race (
pkg/cmd/factory/default.go)
Appwrite
Scores: overall 42.4 (D-), security 2.5, runtime 15.9, testing 2.6, code smell 68.6, dead code 90.3, consistency 99.5, duplication 100.0, compliance 100.0.
Active unresolved issues: 788. Severity mix: critical 15, high 13, medium 742, low 18. Largest categories: Testing 505, Code Smell 214, Dead Code 29, Security 25, Runtime 11, Consistency 4.
The codebase is only 19k lines of code. But the open issues sit directly on authorization boundaries and operational stability paths, producing the lowest overall score in the heritage group.
Examples from analysis_issues:
- DB Connection Exhaustion (
app/init/registers.php) - Missing authorization on database bulk update endpoint (
src/Appwrite/Platform/Modules/Databases/Http/Databases/Collections/Do...) - Missing authorization on VCS repository list endpoint (
src/Appwrite/Platform/Modules/VCS/Http/Installations/Repositories/XLi...)
AI-Heavy
Supabase
Scores: overall 95.5 (A+), security 100.0, runtime 99.5, testing 75.0, code smell 99.8, dead code 100.0, consistency 97.8, duplication 100.0, compliance 100.0.
Active unresolved issues: 16. Severity mix: critical 2, high 3, medium 6, low 5. Largest categories: Consistency 7, Runtime 4, Code Smell 3, Testing 2.
Sixteen issues across 880k LOC. The remaining items are isolated: a broken production import, one weak test assertion, and several very large modules.
Examples from analysis_issues:
- Broken import statement will fail in production deployment (
supabase/functions/search-embeddings/index.ts) - Test missing assertion - propsAreEqual test provides false confidence (
apps/studio/lib/helpers.test.ts) - AuthProvidersFormValidation.tsx (1,628 lines) (
apps/studio/components/interfaces/Auth/AuthProvidersFormValidation.tsx)
Twenty
Scores: overall 85.4 (A-), security 100.0, runtime 70.5, testing 53.2, code smell 90.0, dead code 100.0, consistency 93.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 37. Severity mix: critical 7, high 11, medium 13, low 5, info 1. Largest categories: Testing 18, Runtime 7, Code Smell 4, Consistency 4, Compliance 4.
Security is not the constraint. The active debt sits in workflows, upgrade paths, and service boundaries where runtime safeguards and test coverage have not kept pace with feature surface.
Examples from analysis_issues:
- Auth resolver test is placeholder with no actual assertions (
packages/twenty-server/src/modules/auth/auth.resolver.spec.ts) - Workflow execution E2E tests entirely commented out (
packages/twenty-e2e-testing/tests/workflow-run.spec.ts) - Connection Exhaustion at Scale (
packages/twenty-server/src/engine/core-modules/twenty-config/config-v...)
NocoDB
Scores: overall 79.2 (B), security 61.1, runtime 65.1, testing 71.6, code smell 94.0, dead code 95.9, consistency 98.9, duplication 100.0, compliance 99.9.
Active unresolved issues: 1,280. Severity mix: critical 1, high 21, medium 936, low 203, info 119. Largest categories: Testing 462, Code Smell 451, Dead Code 310, Security 28, Runtime 17, Consistency 10.
Most open debt is medium-severity testing and structure work, with a smaller runtime and security layer around API guards and background job behavior.
Examples from analysis_issues:
- Rate limiting not implemented (
packages/nocodb/src/guards/meta-api-limiter.guard.ts) - API DoS vulnerability (
packages/nocodb/src/guards/) - Circular dependency tendency (
packages/nocodb/src/models/Base.ts)
Cal.com
Scores: overall 70.3 (B-), security 53.6, runtime 69.2, testing 34.5, code smell 81.1, dead code 94.7, consistency 98.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 3,573. Severity mix: critical 5, high 16, medium 3,148, low 403, info 1. Largest categories: Testing 2,398, Dead Code 607, Code Smell 527, Security 29, Runtime 9, Consistency 3.
Testing dominates the volume. The higher-impact issues sit around calendar integration boundaries, crypto handling, repository layering, and skipped verification in booking flows.
Examples from analysis_issues:
- Entire Confirm Handler Test Suite is Skipped (
confirm.handler.test.ts) - Calendar API Rate Limiting (
packages/features/calendars/) - Features Importing from tRPC (
packages/features/)
n8n
Scores: overall 72.6 (B-), security 53.6, runtime 64.7, testing 51.6, code smell 82.0, dead code 95.5, consistency 97.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 4,256. Severity mix: critical 6, high 14, medium 3,266, low 969, info 1. Largest categories: Testing 2,426, Dead Code 1,085, Code Smell 723, Security 17, Consistency 3, Runtime 2.
The profile is dominated by breadth: many untested integration nodes, a large dead-code inventory, and a smaller set of high-impact runtime and security gaps in platform-level services.
Examples from analysis_issues:
- Database connection exhaustion under load (
packages/@n8n/config/src/configs/database.config.ts:79) - Memory leak in job results map (
packages/cli/src/scaling/scaling.service.ts:36) - SSRF vulnerability in HTTP Request nodes (
packages/@n8n/config/src/configs/ssrf-protection.config.ts)
Dify
Scores: overall 70.6 (B-), security 25.8, runtime 93.5, testing 41.7, code smell 92.5, dead code 94.3, consistency 98.6, duplication 100.0, compliance 100.0.
Active unresolved issues: 4,610. Severity mix: high 107, medium 3,696, low 518, info 289. Largest categories: Testing 2,558, Code Smell 861, Security 570, Dead Code 408, Consistency 209, Runtime 4.
The broadest AI-heavy profile in the set. Testing, code smell, security, and dead code are all materially elevated -- this is platform complexity distributed across multiple categories, not one isolated weak spot.
Examples from analysis_issues:
- sqlalchemy.text passes the constructed SQL statement to the database mostly unchanged (
api/controllers/console/app/statistic.py) - God class: WorkflowPersistenceLayer (26 methods, 347 lines) (
api/core/app/workflow/layers/persistence.py) - Frontend-backend API versioning difficulty (
web/service/)
LibreChat
Scores: overall 74.9 (B-), security 60.5, runtime 98.2, testing 15.4, code smell 96.7, dead code 91.3, consistency 97.5, duplication 100.0, compliance 100.0.
Active unresolved issues: 1,533. Severity mix: critical 5, high 14, medium 1,316, low 167, info 31. Largest categories: Testing 1,033, Dead Code 344, Code Smell 74, Consistency 62, Security 14, Runtime 6.
Testing is the constraint. Core service and auth/request layers remain lightly verified, while a smaller set of security and structural issues sits around the surrounding application shell.
Examples from analysis_issues:
- NO tests for data-service.ts (
packages/data-provider/src/data-service.ts) - NO tests for request/auth layer (
packages/data-provider/src/request.ts) waitForwithoutawait- broken tests (client/src/components/Auth/__tests__/Login.spec.tsx)
Vinext
Scores: overall 80.0 (B+), security 96.9, runtime 70.3, testing 48.6, code smell 71.1, dead code 94.7, consistency 78.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 212. Severity mix: critical 2, high 11, medium 180, low 9, info 10. Largest categories: Testing 99, Code Smell 59, Dead Code 34, Runtime 11, Consistency 8, Security 1.
The main weakness is architectural stability in the framework core. Consistency, code smell, and testing issues all point to oversized entrypoints and bidirectional dependencies between layers.
Examples from analysis_issues:
- Circular Dependencies: shims/ to server/ (
packages/vinext/src/shims/server.ts) - God Module: index.ts (4210 lines, 62 imports) (
packages/vinext/src/index.ts) - No Timeout for Route Handler Execution (
packages/vinext/src/server/app-route-handler-execution.ts)
Open SaaS
Scores: overall 53.3 (D+), security 3.4, runtime 24.5, testing 31.4, code smell 98.8, dead code 100.0, consistency 99.6, duplication 100.0, compliance 100.0.
Active unresolved issues: 35. Severity mix: critical 4, high 5, medium 15, low 11. Largest categories: Runtime 15, Security 11, Code Smell 4, Consistency 4, Compliance 1.
Thirty-five issues in a 10k-LOC codebase. Small footprint, but the open issues sit directly on auth, webhook, and query boundaries -- high-impact surface for something this compact.
Examples from analysis_issues:
- Missing authorization in file download URL generation (
template/app/src/file-upload/operations.ts) - Missing webhook idempotency protection (
template/app/src/payment/stripe/webhook.ts) - Race condition in credit decrement (TOCTOU vulnerability) (
template/app/src/demo-ai-app/operations.ts)
Bitchat
Scores: overall 69.1 (C+), security 26.9, runtime 21.9, testing 99.1, code smell 92.8, dead code 100.0, consistency 99.9, duplication 100.0, compliance 100.0.
Active unresolved issues: 39. Severity mix: critical 3, high 9, medium 16, low 11. Largest categories: Runtime 16, Security 10, Code Smell 8, Testing 3, Consistency 2.
Thirty-nine issues, concentrated in concurrency and FFI edges. For a messaging client built on BLE and Tor, that mix has direct runtime and memory-safety implications.
Examples from analysis_issues:
- Race Condition: Concurrent Dictionary Access in BLEService (
bitchat/Services/BLE/BLEService.swift) - Unsafe isAppActive Access from Background Queue (
bitchat/Services/BLE/BLEService.swift) - Null Pointer Dereference in FFI Boundary (
localPackages/Arti/arti-bitchat/src/lib.rs)
Architecture and Dev Practices
The analysis pipeline also evaluates architecture patterns and development practices outside the scoring categories: module boundaries, dependency flows, CI/CD configuration, branch protection, and release engineering. These do not feed into the health score directly but add context.
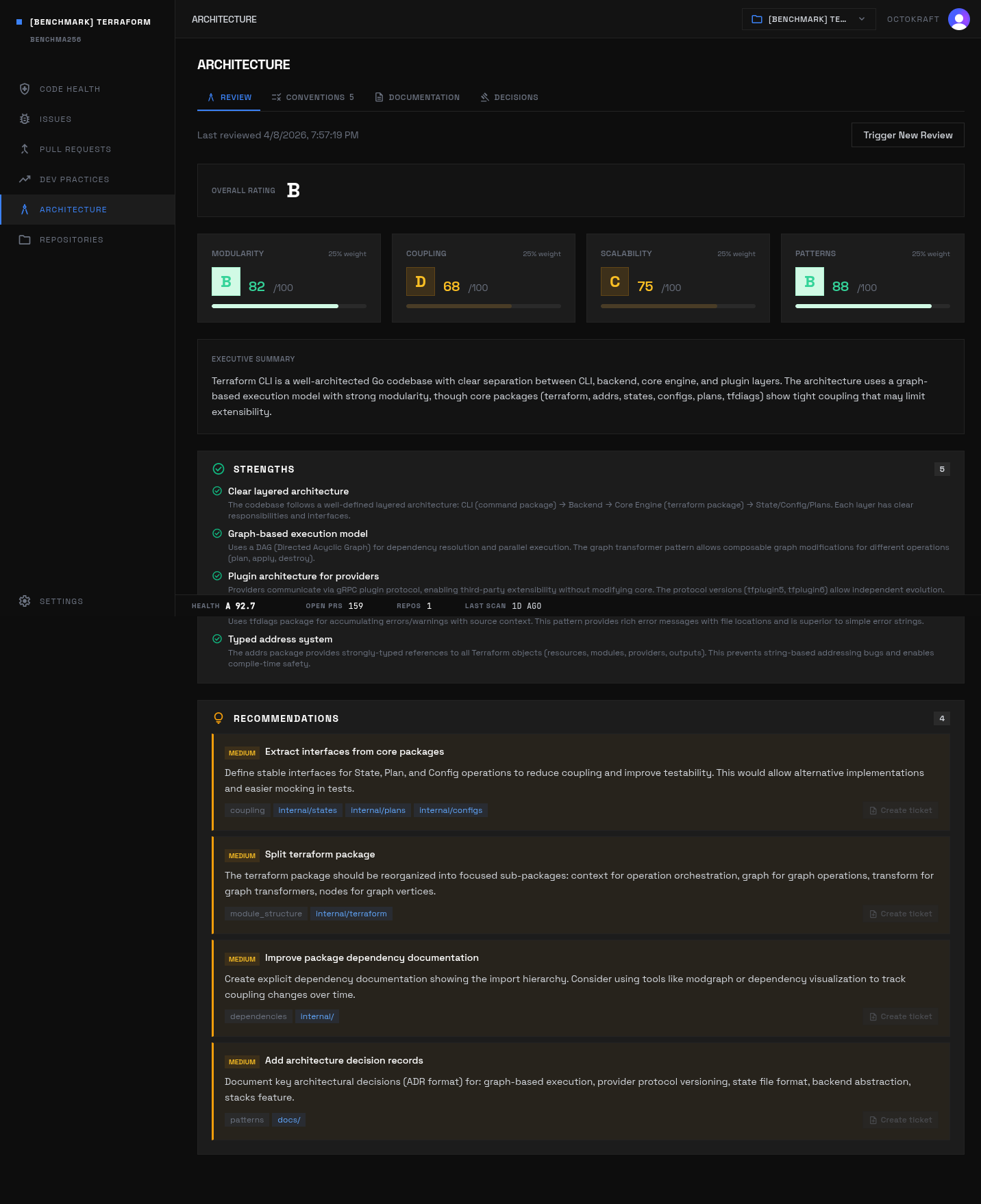
Terraform's architecture review: structural patterns, module boundaries, and dependency flows across the codebase.
Starship's dev practices: CI/CD configuration, branch protection, dependency management, and release engineering.
Methodology
Every project ran through the same four-stage pipeline.
Stage 1: Language detection and static analysis. An LLM agent identifies language ecosystems and selects appropriate static analyzers. Eight language ecosystems are supported. Each gets its own analyzer container targeting production code only; tests, vendored dependencies, build output, and generated files are excluded. A cross-language security scanner runs separately.
Stage 2: Knowledge graph construction. Tree-sitter parsers extract symbols and relationships from source code. The resulting graph supports structural queries: dead code detection, god class identification, circular dependency detection, fan-out measurement, and module coupling metrics. Graph-derived findings go through LLM review to filter false positives from framework patterns, DI containers, reflection, and public APIs.
Stage 3: Behavioral analysis. LLM agents explore the codebase with full filesystem access, targeting specific execution paths and failure modes. A separate test quality analysis examines every test file for shallow assertions, mock overuse, and gaps in critical-path coverage.
Stage 4: Convention detection. Files are grouped by role. An LLM compares analogous files to discover dominant patterns and deviations.
Scoring
Issues are normalized to density against per-category baselines, weighted by severity multipliers (8x for critical down to 0.1x for informational), and run through a sigmoid decay function. Eight category scores combine via weighted average:
- Security (weight 2.0): vulnerabilities, injection risks, authentication gaps, hardcoded secrets
- Runtime risks (weight 1.5): nil dereferences, race conditions, unhandled errors, resource leaks
- Test coverage (weight 1.5): structural coverage, assertion density, test-to-production ratio
- Code smells (weight 1.0): complexity, god classes, high fan-out, naming violations
- Duplication (weight 0.8): copy-pasted logic, repeated patterns across files
- Dead code (weight 0.8): unreachable functions and unused exports, verified via graph analysis
- Consistency (weight 0.7): adherence to the project's own detected conventions
- Compliance (weight 0.5): license headers, documentation standards, configuration hygiene
Letter grades map from A+ (95+) through F (<40). Critical security findings drive steep penalties regardless of codebase size. Every project ran identical pipeline stages, identical severity multipliers, identical category weights. The only variable is the set of static analyzers per language.
Data from Corbulo's analysis of 24 open-source repositories. All projects analyzed with identical rule sets and scoring weights.