The Port
wttr.in is a console weather service that has been running since 2015. Type curl wttr.in/London and you get a weather forecast in your terminal, rendered in ANSI art with colored temperature bands and wind direction arrows. Beneath that one-liner sits geocoding, multiple weather providers, JSON and HTML output, caching, rate limiting, and dozens of query parameters. It handles millions of requests daily. Corbulo's analysis gave it a D-: command injection vulnerabilities, zero Python test coverage, thread-unsafe caching.
That made it a useful target. Complex enough that implementation decisions matter. Small enough for a single agent session.
The Experiment
The same spec was committed to four identical Git repositories. Port wttr.in from Python to Go. Use a free weather API. Single binary, standard library only. Must implement the HTTP server, all output formats, location parsing, caching, rate limiting, and tests. The full Python source was available as reference. Each agent ran in an isolated tmux pane with auto-approve flags. No agent saw another's output.
| Agent | Go Lines | Files | Test Lines |
|---|---|---|---|
| Claude Code | 2,992 | 20 | 932 |
| Codex | 2,473 | 20 | 388 |
| OpenCode | 1,703 | 15 | 365 |
| Gemini CLI | 809 | 12 | 147 |
A 3.7x spread between the largest and smallest implementation for the same spec. All four chose Go's internal/ package convention. All four used the standard library exclusively. Beyond those defaults, the ports diverge in caching strategy, rate limiting, error handling, and how much of the original's behavior they reproduce.
Do They Work?
Start each port. Curl it. Does weather come back?
Three ports return weather for London. Claude Code's output is closest to the original: ANSI terminal formatting with colored temperature bands and wind direction arrows. curl localhost:9001/London?format=3 returns London: ☁️ +12°C. Codex returns weather in clean plain text with full country names and good location resolution. Gemini CLI returns weather but the output format differs from what the original serves.
OpenCode returns "Weather data unavailable" for every city on earth. It compiles. It starts. It listens on the port. It accepts HTTP requests and responds with valid HTTP. It never returns weather data.
The root cause is a function called FetchRaw in the weather client:
var result []byte
_, err = resp.Body.Read(result)result is a nil slice with capacity zero. Read(result) reads zero bytes and returns immediately. The function is not broken in a subtle way. It does nothing. Every call returns an empty byte slice. The cache then stores that empty response, turning a data-fetching bug into a persistent one.
The types align and io.Reader.Read() is called correctly. The bug is semantic: Read reads into the provided buffer, and a nil buffer means zero bytes read. Corbulo flagged it during analysis.
Then there is the /health endpoint. Three out of four ports treat "health" as a city name. Claude Code returns the weather for Health, United States. Codex returns the weather for Health, Arkansas. Gemini CLI returns the weather for a place called Health. OpenCode, the port that cannot fetch weather for any real city, is the only one with a proper health check returning "OK."
What Corbulo Found
All four ports plus the original were analyzed with the same Corbulo pipeline: static analysis, graph-based structural analysis, convention detection, and LLM-powered behavioral assessment.
| Project | Total Issues | Critical | High | Medium | Low |
|---|---|---|---|---|---|
| Claude Code | 52 | 4 | 5 | 31 | 8 |
| Codex | 47 | 6 | 9 | 21 | 11 |
| Gemini CLI | 44 | 5 | 9 | 17 | 8 |
| OpenCode | 42 | 4 | 6 | 22 | 8 |
| Original wttr.in | 38 | 5 | 12 | 18 | 3 |
Issue counts cluster between 42 and 52. The severity profiles differ, and the critical bugs live in behavioral patterns that no linter checks for.
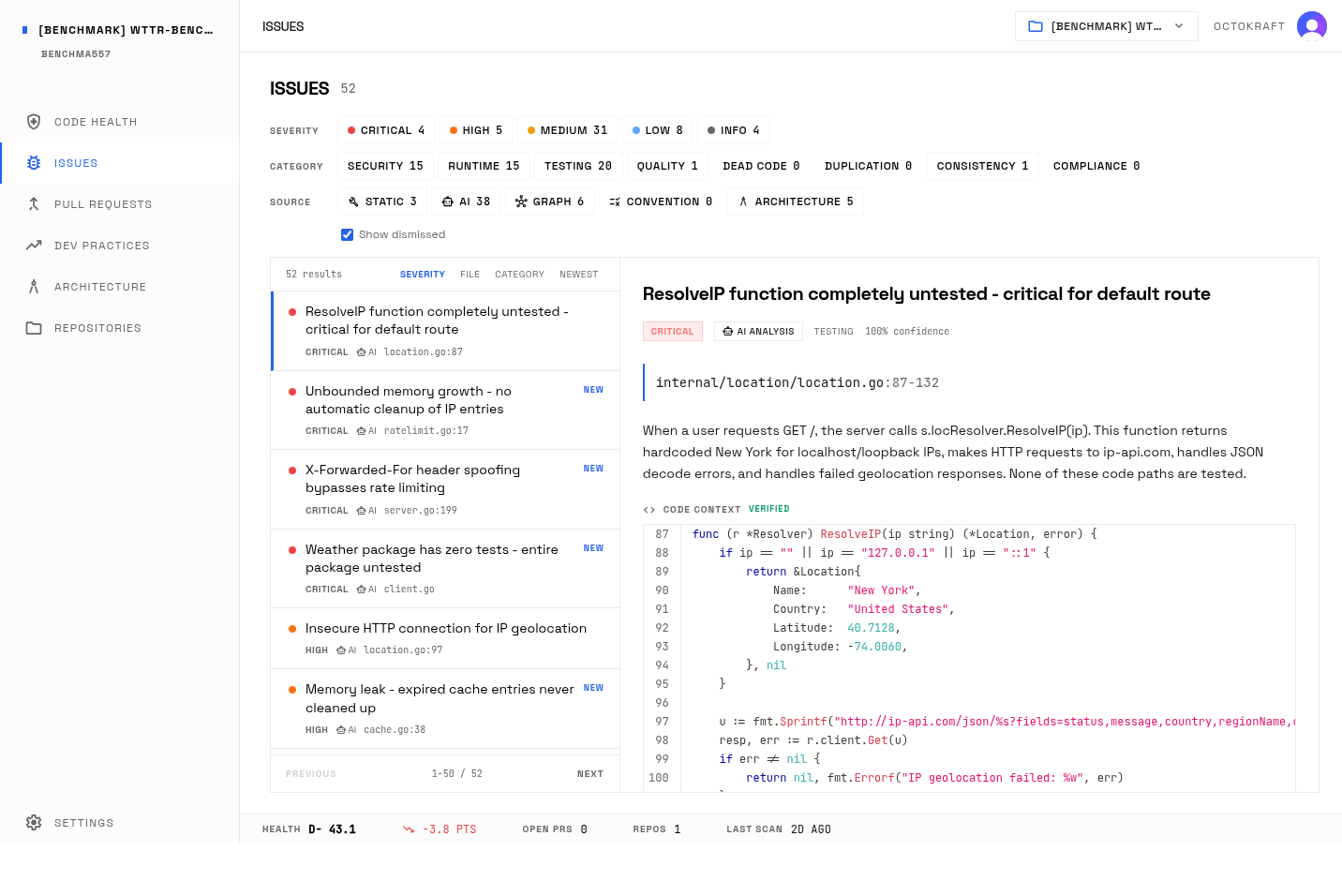
Claude Code's issue list in Corbulo. Security and runtime issues dominate despite clean code structure.
Claude Code: The Cleanup That Never Runs
Claude Code built the most polished internal structure. Seven packages under internal/, zero external dependencies, clean constructor patterns, cache with TTL jitter to prevent thundering herd, IATA airport code lookup, and the most comprehensive test suite. Architecture score: B, with the highest modularity (88) and patterns (90) marks of any port.
The critical bug: the rate limiter has a Cleanup() method that removes expired entries from its windows map. Nothing calls it. The method exists, the goroutine to invoke it does not. Every unique IP address adds a permanent entry. Under real traffic from many IPs, this is an out-of-memory path. The code compiles and the mutex usage is correct. The bug is a missing runtime lifecycle connection. Corbulo flagged the orphaned method.
There is also a design choice the analysis surfaced: denied requests increment the rate limit counter. Once an IP is rate-limited, blocked requests count toward the limit, making recovery slower. Not a bug, but only code-understanding analysis surfaces it.
Codex: The Compound Loopback Bypass
Codex built the most enterprise-structured port. Separate model/ package for pure data, config via environment variables, context propagation throughout (the only port that passes context.Context to external API calls), generic typed cache, graceful shutdown with a 10-second timeout. The only port where client disconnects cancel upstream requests.
The critical bug is a compound vulnerability that only appears when you analyze the interaction between two separate code paths. The rate limiter skips loopback addresses: netip.ParseAddr(ip).IsLoopback() returns true, rate limiting is bypassed. Separately, the server trusts the X-Forwarded-For header without validation. Combine them: an attacker sends X-Forwarded-For: 127.0.0.1 and bypasses all rate limiting. Corbulo connected the two paths during cross-function analysis.
The port also allows a zero or negative HTTP timeout via environment variable. Setting WTTR_HTTP_TIMEOUT=0 creates an HTTP client that waits forever. If the upstream API hangs, the server's goroutines pile up until it dies.
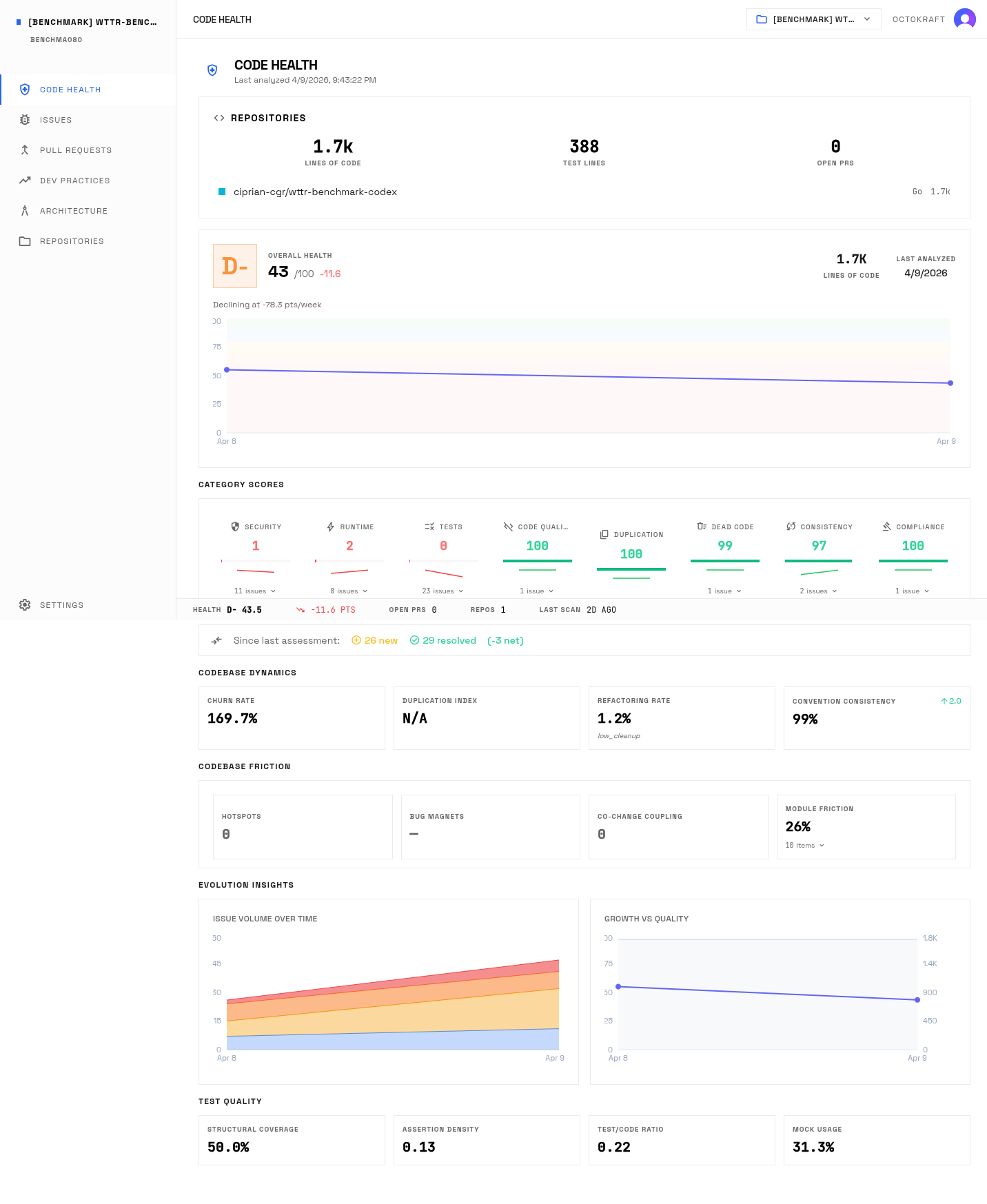
Codex: highest overall score of the four ports. Clean code smell (99.7), but security, runtime, and testing all below 2.0.
Gemini CLI: No Timeout, No Escaping
Gemini CLI built the simplest port. Fewest lines, fewest files, fewest abstractions. Free functions instead of struct methods for weather and location, no dependency injection, sync.Mutex chosen over sync.RWMutex for simplicity. Readable code.
Two critical bugs. First, both weather.Fetch() and location.Search() use http.Get() with Go's default HTTP client, which has no timeout. If the upstream API hangs, the goroutine blocks indefinitely. Under load, a slow upstream causes goroutine exhaustion and the service dies. This is the most operationally dangerous bug across all four ports. The call is valid. The default client just has no timeout, and nothing in the code sets one. *Corbulo* flagged the missing timeout during behavioral analysis.
Second, the renderHTML function embeds terminal output directly into HTML via fmt.Sprintf without any escaping. Location names from the geocoding API flow straight into the response body. Unlike Claude Code's custom escaper (incomplete but present) or OpenCode's partial html.EscapeString, Gemini CLI has zero HTML escaping. This is exploitable XSS.
The test suite also calls real external APIs. The tests are flaky by design: they fail when Open-Meteo or ip-api.com is down, and they cannot test error paths. The tests depend on third-party uptime and cannot verify error handling paths.
OpenCode: The Function That Does Nothing
Beyond the FetchRaw nil-slice problem, OpenCode has a second critical bug: formatTemp accesses temp[0] without checking if the string is empty. If the upstream API returns an empty temperature, the entire service panics with an index-out-of-bounds crash.
There are also two URL injection vulnerabilities. User-supplied location names are interpolated directly into URLs via fmt.Sprintf without encoding. The geocoding client applies only strings.ReplaceAll(query, " ", "+") as sanitization. Special characters pass through untouched. Since OpenCode proxies to the original wttr.in rather than calling Open-Meteo directly, this is an SSRF vector against the upstream service.
The test suite checks only that results are not empty strings. The JSON test does not validate JSON syntax. The ANSI test does not verify temperatures appear in output. These tests pass for any non-empty string, providing zero behavioral verification. The LLM flagged this. A static analyzer sees test functions that call production code and check return values.
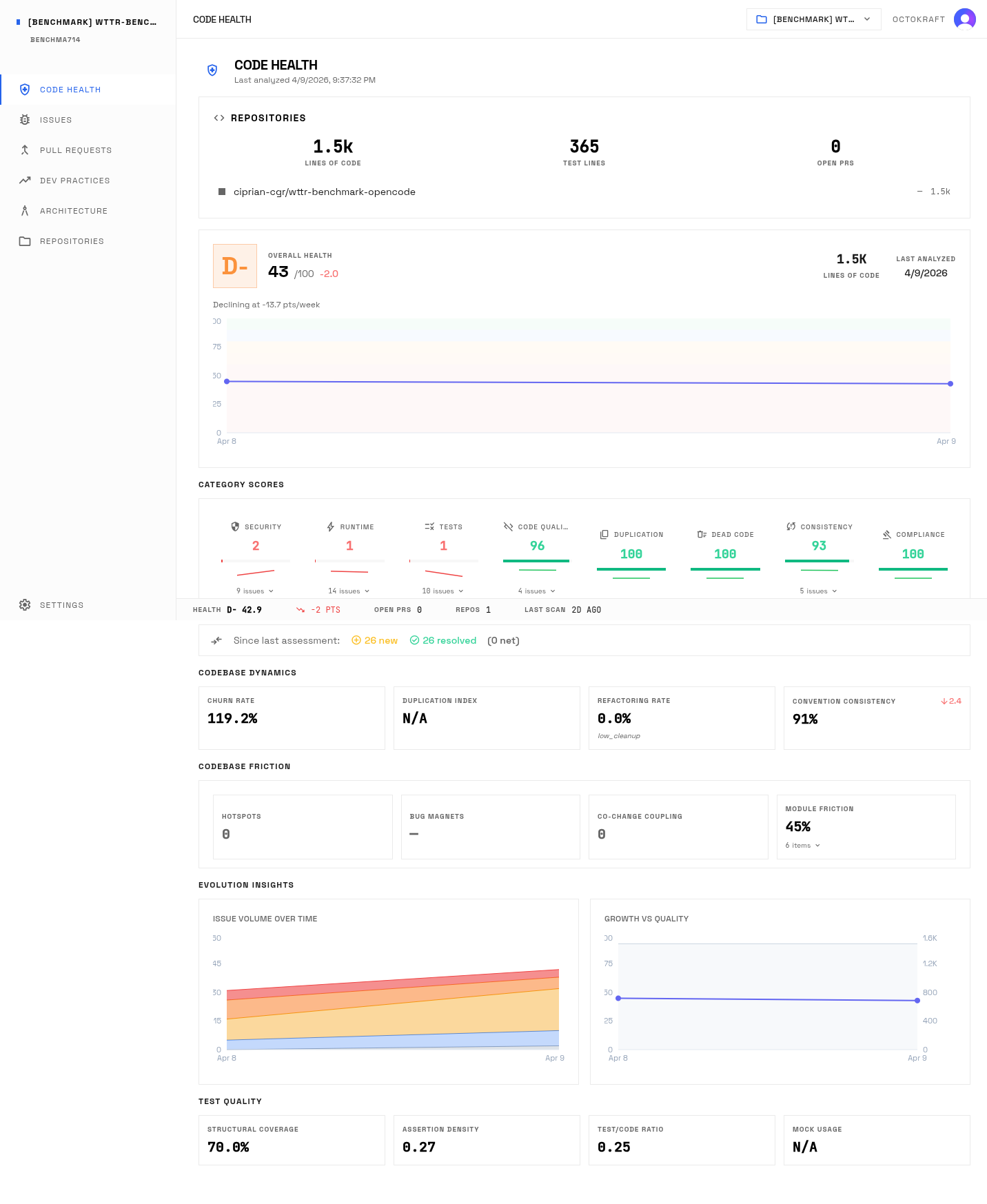
OpenCode: the port that compiles and runs but never returns weather data.
What Every Agent Got Wrong
Some bugs appeared independently in all four ports:
- Unbounded rate limiter map. Every port stores per-IP rate limit data in a map that grows without bound. Claude Code has a
Cleanup()method but never calls it. The other three have no cleanup mechanism at all. Under sustained traffic from many unique IPs, all four eventually run out of memory. - X-Forwarded-For trust. All four ports trust the header blindly. None implement trusted-proxy lists. None documented this assumption or made it configurable.
- No coordinate validation. Latitude 999 and longitude -500 pass through to external APIs unchecked.
- No proactive cache cleanup. All four use lazy eviction. None run background goroutines for expired entries.
Architecture
All four ports received a B on architecture review. The original wttr.in received a C.
| Metric | Original (C) | Claude (B) | Codex (B) | Gemini (B) | OpenCode (B) |
|---|---|---|---|---|---|
| Modularity | 62 | 88 | 75 | 85 | 78 |
| Coupling | 55 | 82 | 80 | 80 | 72 |
| Patterns | 58 | 90 | 85 | 75 | 75 |
| Scalability | 72 | 68 | 65 | 65 | 65 |
Claude Code leads on modularity, coupling, and patterns. Each package has a single responsibility. The NewWithDeps() constructor enables test injection. Codex is the only port with externalized configuration, graceful shutdown, and context.Context propagation. Gemini CLI packed the most functionality into the fewest lines but had no configuration management and no request timeouts. OpenCode chose to proxy the original wttr.in instead of calling Open-Meteo directly, a valid decision that was never tested against the upstream format.
Scalability is the one metric where the original leads. A decade of production hardening gave it connection pooling and request coalescing. None of the ports implemented connection pooling for upstream calls.
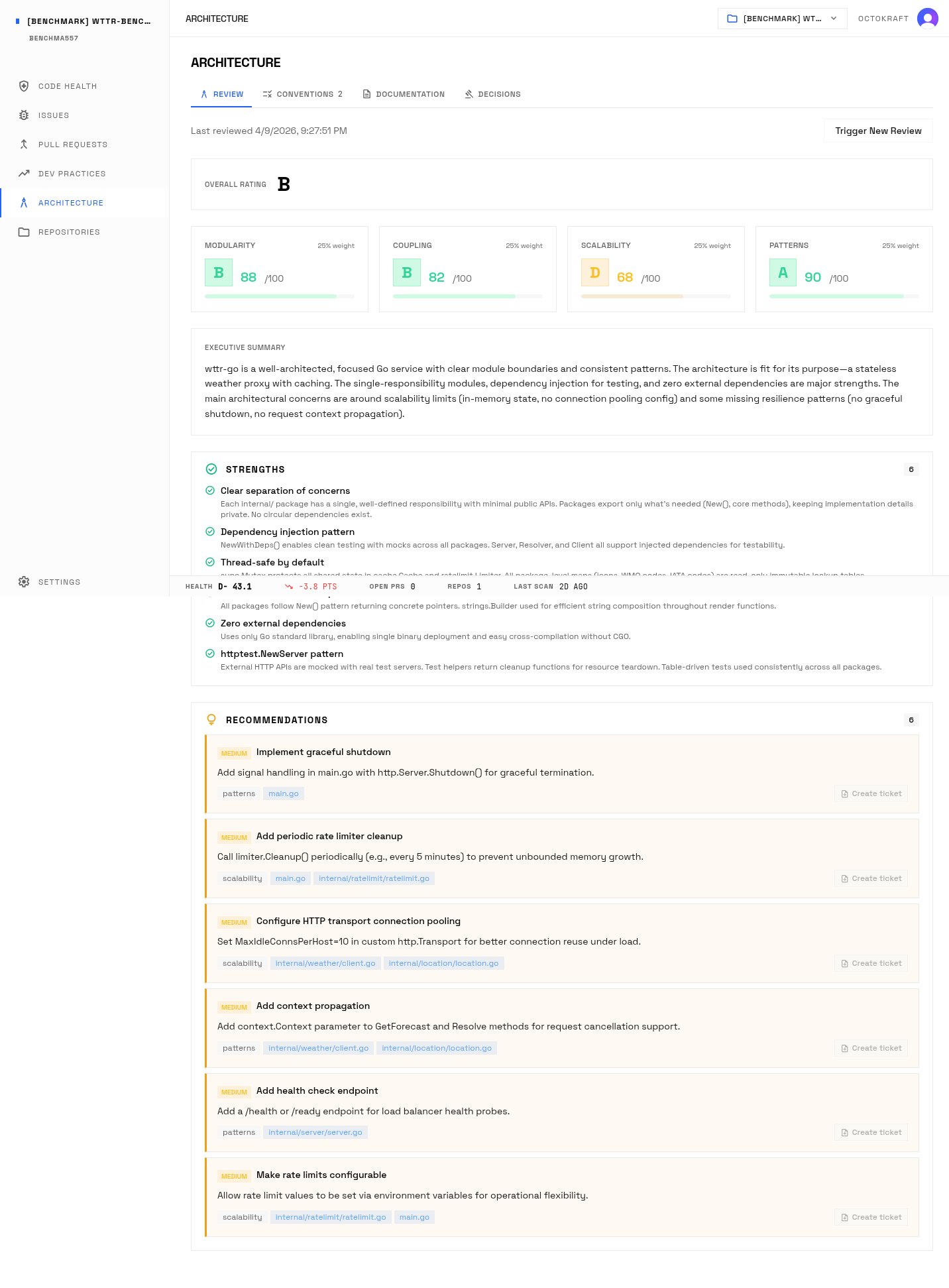
Claude Code's architecture review: clean package separation with single-responsibility modules.
Autonomous QA
All four ports were containerized, deployed to isolated Kubernetes namespaces, and tested by an autonomous QA agent. The agent uses a planner-executor architecture: a planning agent generates test missions, then executor agents independently run each mission using curl, k6, and browser tools. Five missions ran identically against all four ports: functional output, edge cases, security, reliability, and API contract validation.
| Mission | Claude | Codex | Gemini | OpenCode |
|---|---|---|---|---|
| Functional | FAIL (5) | PASS (1) | FAIL (9) | FAIL (5) |
| Edge Cases | TIMEOUT | FAIL (3) | FAIL (3) | INCONCLUSIVE |
| Security | FAIL (4) | FAIL (1) | INCONCLUSIVE | FAIL (3) |
| Reliability | FAIL (5) | FAIL (1) | FAIL (8) | INCONCLUSIVE |
| API Contract | TIMEOUT | FAIL (5) | TIMEOUT | FAIL (6) |
Codex was the only port to pass a mission. Its core weather output worked correctly across all output formats. Gemini CLI accumulated the most bugs across both testing rounds: 55 total, including the XSS and a crash under 20 concurrent users that restarted its Kubernetes pod.
| Metric | Claude | Codex | Gemini | OpenCode |
|---|---|---|---|---|
| Missions passed | 0/5 | 1/5 | 0/5 | 0/5 |
| Total bugs (both rounds) | 33 | 29 | 55 | 23 |
Experiment 2
The Fix
NocoDB bug: when infinite scrolling is disabled, linking or unlinking a BelongsTo relation does not update the grid cell. Root cause: the view refresh trigger in useLTARStore.ts is guarded behind a condition that never fires for non-infinite-scroll grids.
Each agent received the same bug report on a fork of NocoDB and worked on its own branch. Corbulo's PR analysis pipeline ran an 11-phase Temporal workflow against each PR.
| Agent | Strategy | Lines Changed | Fixed Root Cause? | Tested? |
|---|---|---|---|---|
| Claude Code | Remove guard in useLTARStore, add regression test | 14 fix + 232 test | Yes | Yes |
| Codex | Add row reload helper in Row.vue | 58 fix + 47 test | No | Yes |
| Gemini CLI | Remove guard in useLTARStore | 18 fix | No (partial) | No |
| OpenCode (GLM 5.1) | Remove guard in useLTARStore | 3 fix + 8 removed | Yes | No |
Two agents fixed the root cause. Two did not. The approaches diverged significantly despite the same bug report.
What Corbulo Found
| Agent | Classification | Blocking | Advisory | Risk Signals | Health Delta |
|---|---|---|---|---|---|
| Claude Code | bugfix | 0 | 5 | none | +11.6 (B- to B+) |
| Codex | bugfix | 1 | 6 | data_sync, ui_state | +10.4 (B- to B+) |
| Gemini CLI | bugfix | 0 | 6 | small_change | +11.5 (B- to B+) |
| OpenCode | bugfix | 0 | 2 | small_change_scope | 0 (B- stays B-) |
No scope drift. No false infrastructure signals. These are clean diffs against the correct base branch, showing only what each agent actually wrote.
How the Fixes Differ
Claude Code is the most complete submission. It removes the broken guard on both the link and unlink paths, adds a 232-line regression test suite that covers the exact contract the bug broke, and correctly identifies that reloadViewDataTrigger needs to be injected rather than conditionally created. The test coverage projection jumps from 31 to 99.9. Five advisory findings, zero blocking.
Codex adds a reloadRow helper and wires it into Row.vue, which improves local component behavior. But it never removes the broken guard in useLTARStore.ts. The root cause remains. The helper and its test are real improvements, which is why the health projection is strong (+10.4). But the bug still exists. One blocking finding: the approach introduces a data synchronization risk because it reloads at the wrong layer.
Gemini CLI removes the guard, which is the right idea. But it only addresses part of the condition and adds no test. The fix is directionally correct but incomplete. Six advisory findings, zero blocking. The health improvement (+11.5) comes from the code change itself, not from added verification.
OpenCode (GLM 5.1) produces the smallest and cleanest diff: +3/-8 lines. It removes the guard on both paths and simplifies the reloadViewDataTrigger initialization. Correct root-cause fix. Two advisory findings, zero blocking. But no test, so the health score does not move. The first attempt with GLM-5 failed entirely. The model explored the codebase correctly across two sessions (27 minutes and 6 minutes, reading 20+ files) but could not transition from reading to writing. It produced garbled code inline instead of calling the file-edit tool, then stopped. GLM 5.1 fixed the bug in a single run.
Health Projection
| Category | Current | Claude | Codex | Gemini | OpenCode |
|---|---|---|---|---|---|
| Test Coverage | 31 (F) | 99.9 (A+) +68.7 | 99.9 (A+) +68.7 | 99.6 (A+) +68.4 | 31 (F) 0 |
| Runtime Risks | 100 (A+) | 99.4 -0.6 | 92.6 -7.4 | 99.2 -0.8 | 100 (A+) |
| Overall | 73.2 (B-) | 84.9 (B+) +11.6 | 83.7 (B+) +10.4 | 84.8 (B+) +11.5 | 73.2 (B-) 0 |
Three agents project to B+. OpenCode stays at B- because it adds no tests despite fixing the root cause. Codex projects well despite missing the root cause because it adds test infrastructure. Health projection measures what a PR adds to the codebase. It does not measure whether the bug is actually fixed.
Agent Profiles
Two experiments with the same four agents. The port tests whether an agent can build something from a spec. The fix tests whether it can debug something in an existing codebase. The data from both experiments draws a consistent profile for each.
| Claude Code | Codex | Gemini CLI | OpenCode | |
|---|---|---|---|---|
| Port: works? | Yes | Yes | Yes | No |
| Port: grade | D- (43.1) | D- (43.5) | F (29.8) | D- (42.9) |
| Port: architecture | B (88/82/90/68) | B (75/80/85/65) | B (85/80/75/65) | B (78/72/75/65) |
| Port: QA bugs | 33 | 29 | 55 | 23 |
| Port: missions passed | 0/5 | 1/5 | 0/5 | 0/5 |
| Port: headline bug | Cleanup() never called | Loopback bypass | No timeout, XSS | FetchRaw nil slice |
| Fix: root cause? | Yes | No (nearby) | Partial | Yes |
| Fix: blocking issues | 0 | 1 | 0 | 0 |
| Fix: health delta | +11.6 (B+) | +10.4 (B+) | +11.5 (B+) | 0 (B-) |
Claude Code
Strongest structure, broadest tests, missing lifecycle wiring. Port: Cleanup() written but never connected, root endpoint returns 404. Fix: only agent to both fix the root cause and add a comprehensive regression test. Builds the best architecture. Does not always verify everything is plugged in.
Codex
Strongest production-oriented structure, compound security mistakes. Port: context propagation, graceful shutdown, typed cache. But loopback bypass via two correct-looking paths. Fix: properly structured helper with a test, but targets the wrong layer. The broken guard in the store remains. Same pattern as the port: builds good infrastructure around a core problem it does not address.
Gemini CLI
Smallest readable implementation, weakest operational safeguards. Port: fewest lines, no timeouts, zero escaping, crashed under load. Fix: directionally correct (removes part of the guard) but incomplete, no test. Consistent pattern: minimum viable change without surrounding verification.
OpenCode (GLM 5.1)
Interesting extensibility patterns, model capability gap on first attempt. Port: best interface design, FetchRaw reads into nil slice. Fix: GLM-5 failed to write any code across two sessions despite correctly identifying the bug. GLM 5.1 produced the cleanest root-cause fix in a single run (+3/-8 lines), but no test.
Findings That Required Behavioral Analysis
| Finding | Experiment | Agent | Why This Is Hard to Catch |
|---|---|---|---|
| Cleanup() exists but nothing calls it | Port | Claude | Code compiles, mutex correct, method valid |
| Loopback skip + XFF trust = full bypass | Port | Codex | Each path individually correct |
| Default HTTP client has no timeout | Port | Gemini | http.Get() is a valid stdlib call |
| Read() into nil slice reads zero bytes | Port | OpenCode | Types align, Read() called correctly |
These findings require understanding code behavior across function boundaries, runtime lifecycle, and concurrent execution semantics. The code is valid at the syntax and type level. Corbulo's analysis catches what goes wrong at runtime: orphaned lifecycle methods, compound interaction paths, semantic misuse of standard library contracts.
Cross-Experiment Consistency
The two experiments describe the same agents from different directions, and the fingerprints match.
Claude reasons correctly about the focal control-flow problem in both experiments, then leaves surrounding lifecycle wiring less fully checked. Codex builds the most production-shaped infrastructure in both experiments, but the core problem goes unaddressed: loopback bypass in the port, wrong-layer fix that leaves the root cause intact in the bugfix. Gemini produces the minimum viable change in both experiments: fewest lines in the port, partial guard removal with no test in the fix. OpenCode has the most interesting extensibility design in the port and the cleanest fix once the model was upgraded, but core functionality failed to land on the first attempt in both experiments.
Package structure converges quickly across agents. Root-cause identification and verification discipline do not.
Methodology
Port experiment. Same spec committed to four identical repositories. Each agent ran in isolation with auto-approve flags. All four ports plus the original analyzed with Corbulo's full pipeline. QA testing by an autonomous QA agent across two rounds.
Fix experiment. Each agent received the same bug report on a fork of NocoDB. Corbulo's PR analysis pipeline ran an 11-phase Temporal workflow against each PR: classification, code quality agent, impact analysis agent, convention drift agent, static analyzers, graph impact, conflict detection, deduplication, health projection, merge readiness, and GitHub review posting. All four PRs were also reviewed by OpenAI's Codex bot.
Scoring. Health scores weight security, runtime risks, and testing most heavily.